

t検定は、母分散未知の場合の母平均の検定のことです。
実務でもよく使われます。

平均値に差があるかどうか?を議論したい時は多くありますが、母分散がわかっているケースというのは稀ですからね。
母分散既知の場合の母平均の検定
t検定(母分散未知の場合の母平均の検定)を理解するには、まずは「母分散既知の場合の母平均の検定」を理解する必要があります。

簡単におさらいしておきましょう。
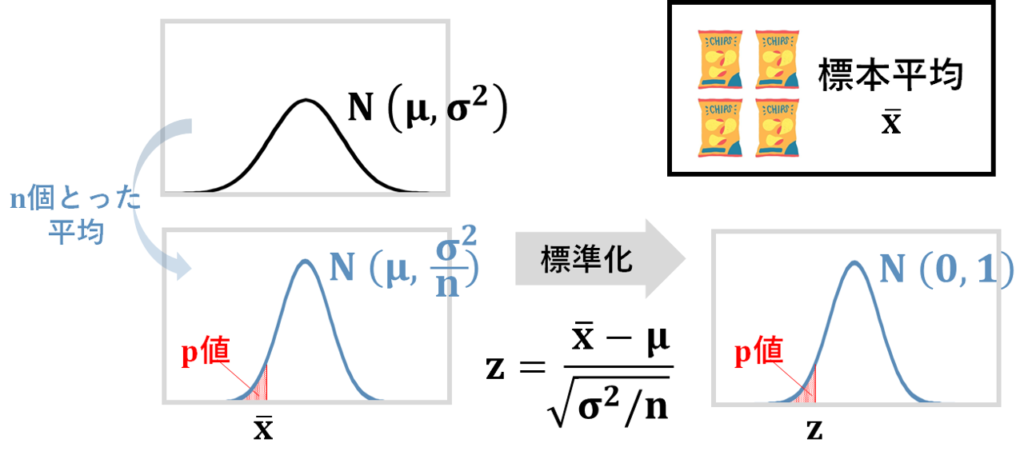
ここでの帰無仮説は、「これらのデータ(標本平均の計算に使った実際のデータ)は、この母集団(平均、分散の正規分布)からとってきたデータである」です。
帰無仮説が正しいと仮定したときの母集団は、平均、分散の正規分布になりますね。
平均を議論するので、まずは、平均が従う分布を考えます。
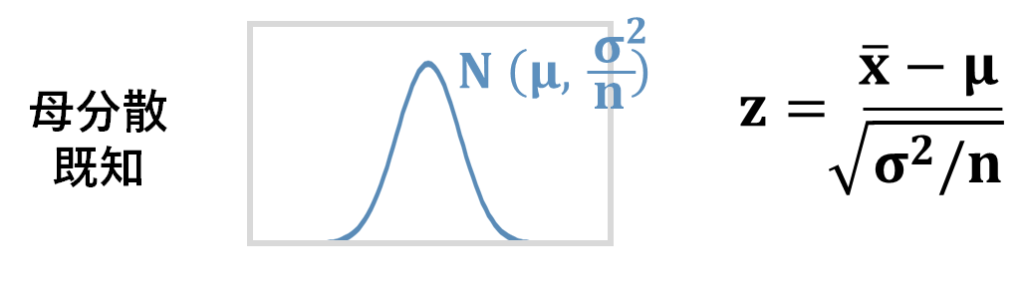
平均、分散の正規母集団から、個とってきた標本の平均が従う分布は、平均、分散の正規分布ですよね。
帰無仮説が正しいなら、実際の標本平均はこの分布に従うはずです。
帰無仮説が正しいと仮定した時に、実際の標本平均以上に極端な観測値がどのくらいの確率で発生しうるのか(これを値と言います)、これが知りたいので、この分布を標準化して標準正規分布にして考えます。

標本平均が分布の裾にあれば、値が小さくなりますね。
値が小さいということは、「もし帰無仮説が正しいのであれば、すごくレアなことが起こった」ということを意味するので、値が小さい場合には、帰無仮説が正しいと仮定したこと自体が誤りだったのではないか、と考えます。
さて、母分散既知の場合は、このように、標本平均が従う分布を標準正規分布に変換して値を算出する、ということをやりましたが、この記事で扱うのは母分散がわかっていない場合です。
母分散が未知ということは、この式の中のの部分がわかっていない状況でどうやって値を計算するのか?というところがポイントになりますね。
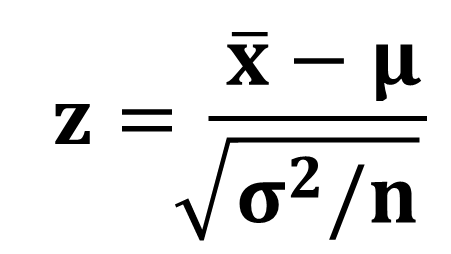
母分散未知の場合どうする?
母分散が既知の場合に標本平均が従う分布は、平均、分散の正規分布で、これを標準化するために、この式を使いましたね。
母分散未知の場合も同じように標準化したいのですが、母分散が分からない状態なので困ってしまいますよね。
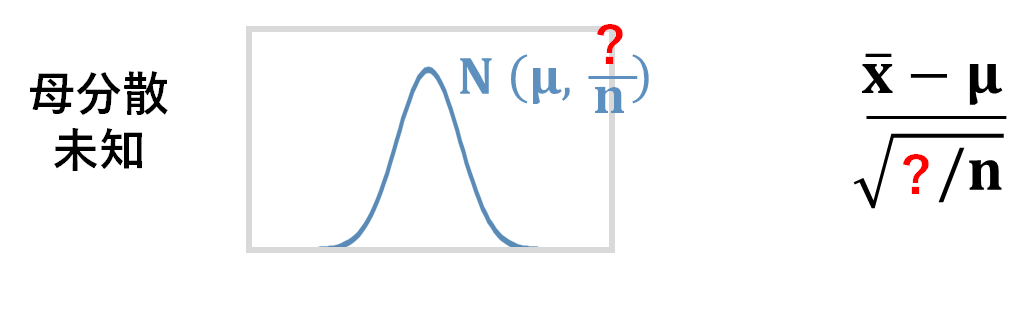
母分散がわからないのであれば、標本から推定しようという発想になりますよね。
標本から母分散を推定する際には、不偏分散を使用するのでしたね。
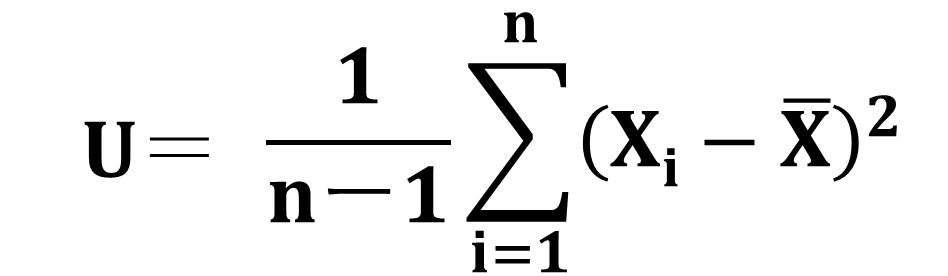
母分散の代わりに不偏分散を使うとこの式はこうなります。
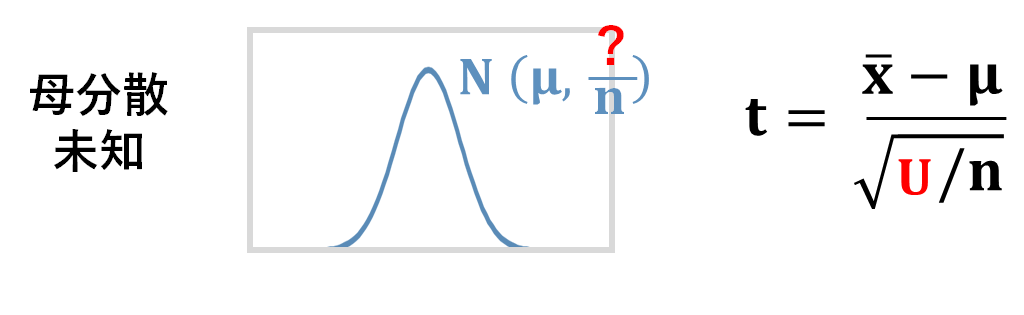
ところがここで問題があります。
は母分散なので、ある決まったひとつの値です。
だから、母分散既知の場合の標準化の式(スコアの計算式)における確率変数は、標本平均だけでした。
しかし、今回は、を不偏分散に置き換えたわけですが、不偏分散は標本で計算した値なので確率変数なんです。
つまり、分母にも分子にも確率変数があるということです。
言い換えると、分子がある確率分布で変動するし、分母がまた別の確率分布で変動する、ということです。
確率分布÷確率分布を考えなければならないので、ややこしい状態というわけです。
分子が従う分布は正規分布です。これは容易にわかりますよね。
分母にある不偏分散が従うのは、カイ二乗分布という分布です。
「正規分布÷カイ二乗分布の平方根」は、いったいどんな分布になるのでしょうか?
これを研究して、その分布を発見したのが、ウィリアム・ゴセットさんという方で、その分布がt分布なんです。 この式の計算結果がt分布に従うため、この計算によって得られる値には、t値という名前がついています。
t分布
t分布はこのような形状をしています。正規分布と似ていますね。
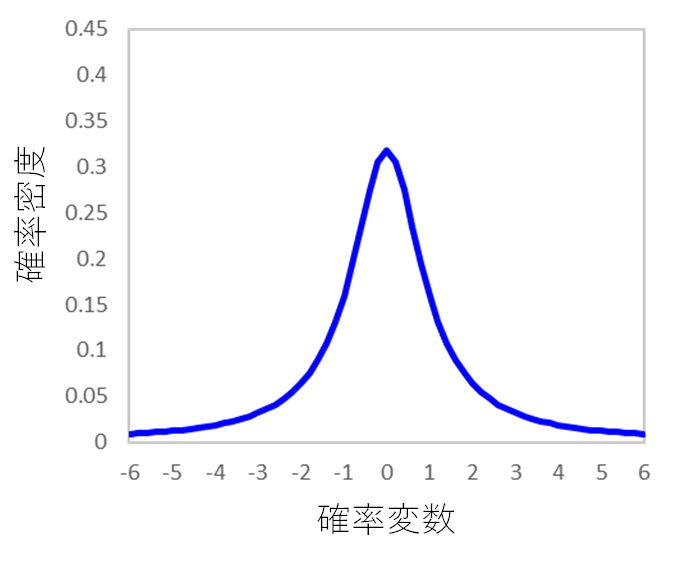
正規分布と似てはいるのですが、実は正規分布よりも裾引きが多くなっているんです。
不偏分散は、それを計算するデータの数が多いほど、その計算結果の確からしさは高くなりますよね。
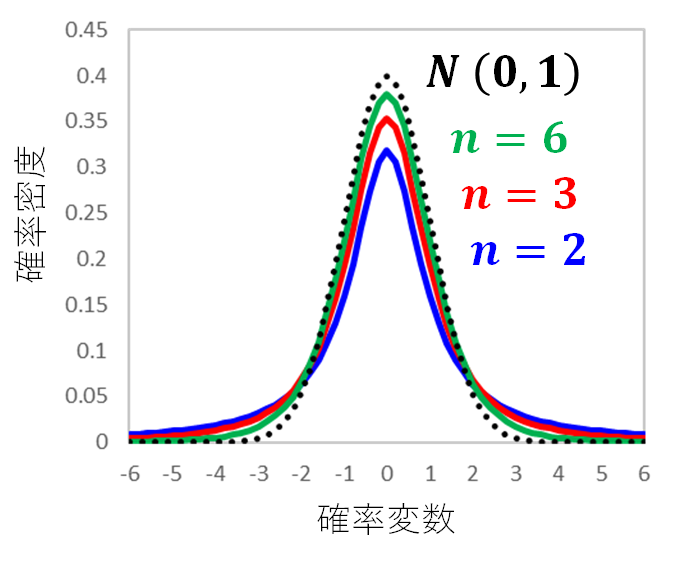
だから、が大きくなるほど、この裾引きは少なくなっていくんです。
そして、が無限大になると、標準正規分布と一致します。
が無限大の時の不偏分散は、もはや不偏分散ではなく母分散になりますので、t値の計算式の分母からは確率変数がなくなるため、標準正規分布になるんですね。
正規分布を標準正規分布に変換する式のの部分を不偏分散で置き換えたわけですから、t分布の元は標準正規分布なんです。
だから、t分布の中心は0なんです。
t分布は、このように標本平均を計算するデータ数が変わると分布の形状が変わる性質があります。
分母に不偏分散を使用しているから、t分布を使う必要があるわけなので、t分布の形状は不偏分散の分母にある自由度に依存するんです。
t分布は、このように示されます。カッコ内は自由度です。
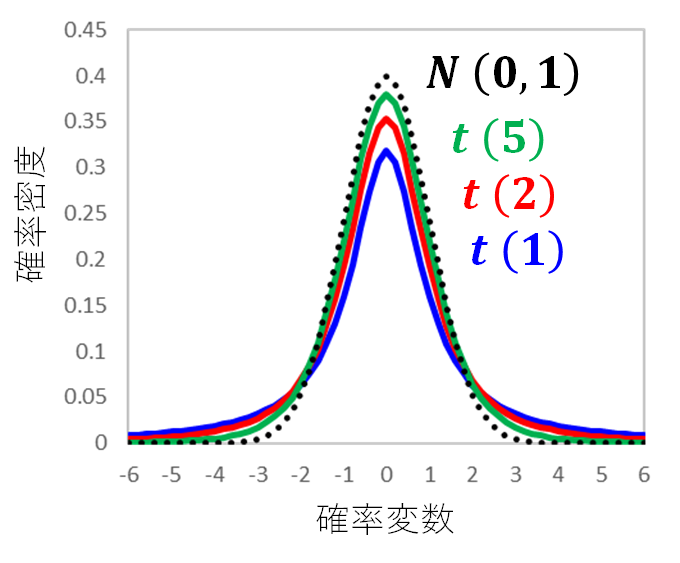
t分布の中心は0なので、分布の裾の広がり方さえわかればt分布の形状が決まります。
正規分布は、平均(中心)と分散(裾の広がり方)がわかれば決まりましたが、t分布は中心は0なので、裾の広がり方だけで決まる(つまり、自由度が決まれば決まる)ということです。
t分布の性質は理解できましたでしょうか?
これがわかれば、あとは、母分散既知の場合の検定の進め方と同じです。
違うのは、値の計算に、標準正規分布を使うのかt分布を使うのか?です。
t検定
実際にやってみましょう。
状況としては、母分散既知の場合の解説に用いた例題と同じで「母分散が不明である」というところのみ異なることにしましょう。
ある製品には内容量が100gと記載してある。
しかし、Aさんは、この製品の内容量が100gよりも少ないのではないかと感じている。
この製品4この重さの実際の平均値は98gであった。内容量の平均が100gよりも少ないと言えるか?
※内容量の分布は正規分布に従っているとする。

Aさんが、大好きな製品の内容量が、100gよりも少なくなったんじゃないかと怪しんでいる、という状況ですね。
そして、4この製品の実際の重さの平均値を計算したら、98gだった、という状況ですね。
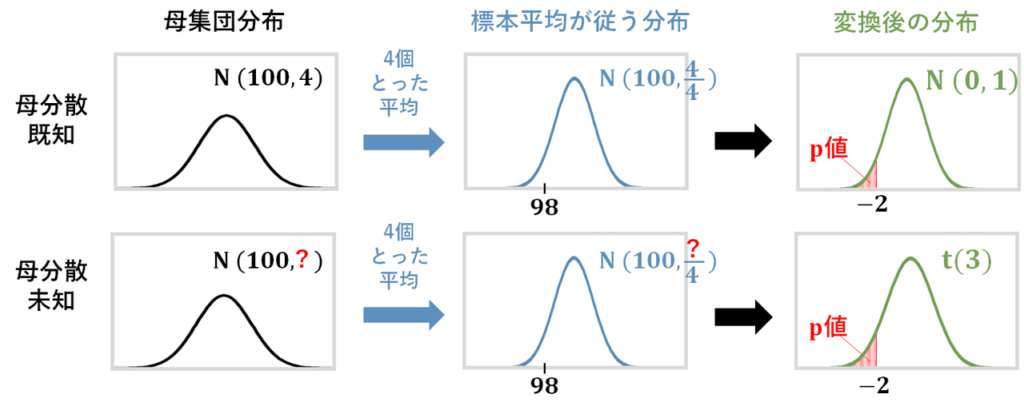
帰無仮説が正しいと仮定したときの標本平均が従う分布は、平均は元の分布と同じ、分散は元の分布の分散÷4になりますよね。
母分散既知の場合は、標本平均が従う分布における98が、標準正規分布ではいくつに相当するかを求め、そして、標準正規分布表を読み取って値を求めればよいですよね。
N(100,4)における98は、標準正規分布上では-2に相当します。
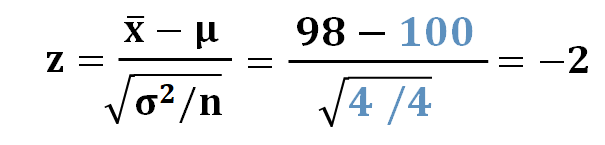
値は標準正規分布表を読み取って、0.02275です。
有意水準を0.05とするなら、帰無仮説は棄却される(つまり、100gよりも少なくなったとは主張できる)ということですね。
母分散未知の場合は、母分散のかわりに不偏分散を使うので、変換後の分布は標準正規分布ではなくt値になるのでしたね。
今回は、4つのデータで不偏分散を計算するので、t分布の自由度は3です。
不偏分散の計算結果は、今回は4(母分散と同じ)だったとすると、実際のデータで計算したt値は-2になりますね。
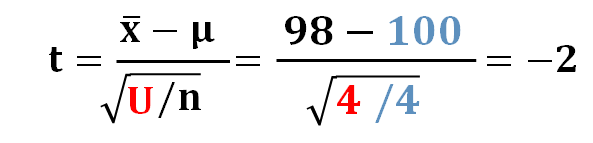
次は、母分散既知の場合と同じように、 t値が自由度3のt分布上ではどこにあるのかをチェックして、その観測結果およびそれ以上にレアなことが起こる確率値を求めます。
母分散既知の場合の母平均の検定では、標準正規分布表を使いましたが、今回は、t分布表を使います。
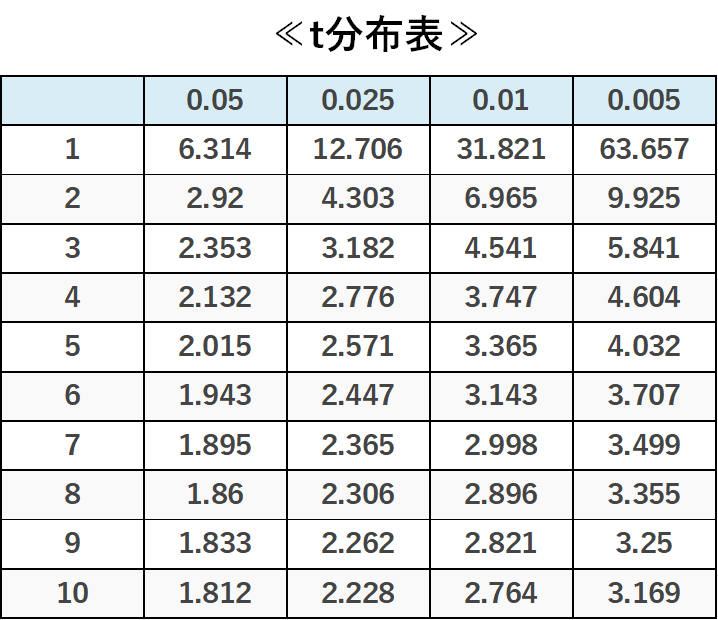
t分布では、『自由度』がからんでくるので、標準正規分布表とは、読み方がちょっと異なります。
自由度3で確率が0.05の時のt値は、縦軸:3、横軸:0.05がクロスする箇所を読み取ります。
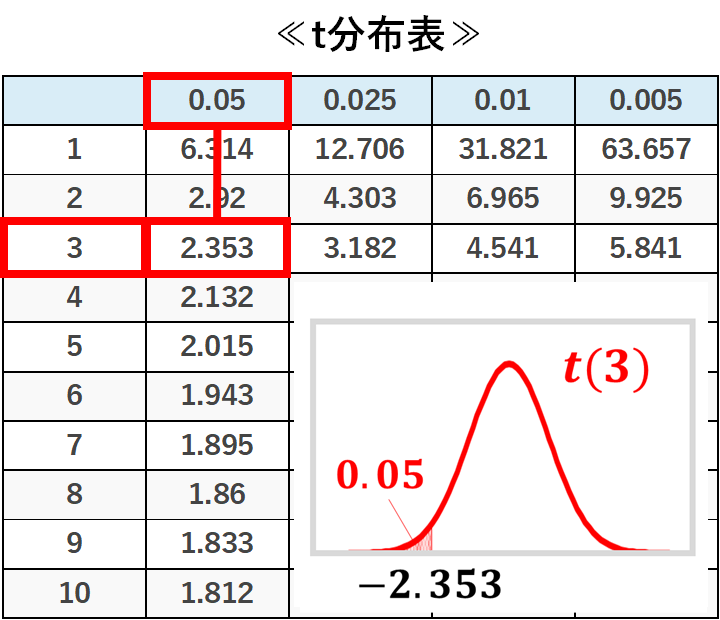
これは、自由度3のt分布では、-2.353以下の発生確率が0.05ということです。
あれ?標準正規分布表では、値から値がわかったのに、
t分布表でわかるのは、自由度が3の時に値が0.05になる時のt値なんですね。
t値が2の時の値は直接わからないんですね。
そうなんです。
t分布は自由度もからむため、自由度×t値で値を記載しようとすると情報量が莫大になってしまうため、このような書き方をされているんでしょうね。
しかし、よく考えてみると、これで十分事足りるんです。
我々が知りたいのは、値が0.05よりも大きいのか小さいのかです。
帰無仮説を受容するのか棄却するのかを判断するのに、正確な値は必要ないんですね。
だから、『値が0.05の時というのは、t値がいくつの時なのか?』がわかれば、それと比べて実際のt値が大きいのか小さいのかで、値が0.05よりも大きいのか小さいのかがわかりますからね。
さて、今回、t値の絶対値は、t分布表で、自由度3、確率0.05のクロスする部分に書いてある値である2.353よりも小さいです。
ということは、値が0.05よりも大きい、ということですね。
ということは、帰無仮説の矛盾を主張できないので、帰無仮説を受容する(つまり、100gよりも少なくなったとは主張できない)ということになりますね。
値(母分散既知の場合の検定統計量)もt値(母分散未知の場合の検定統計量)も-2であるのに、母分散既知の場合は、帰無仮説は棄却され、母分散未知の場合は帰無仮説は受容されましたよね。
標準正規分布よりもt分布のほうが分布の裾引きが大きいので、母分散既知のときよりも母分散未知の時のt検定のほうが帰無仮説が棄却されにくいということがこの例からわかりますね。
これは、不偏分散はばらつきを持つ確率変数であるため、時には母分散よりも大きく計算されてしまう可能性があることを考慮しているからです。
不偏分散の計算に使用するデータ数を増やせば、不偏分散の計算結果は、母分散から大きく外れる可能性が低くなるので、t分布の裾引きは小さくなります。
このことは、t分布表で自由度が増えるほど、特定の値となる時の t値が小さくなっていることからもわかると思います。
注意点
ここで、t分布表から読み取れるのは、ある自由度のt分布において、値がある値になる時のt値ですよね。
値がある値になる時のt値は、片側検定か両側検定かで変わります。
「ある値よりも大きいかどうか」や「ある値よりも小さいかどうか」を議論する場合には片側検定をすることになりますので、片方の裾の部分の面積が議論の的ですよね。
「ある値かどうか」を議論する場合には両側検定をすることになりますので、両方のの裾の部分の面積が議論の的ですよね。
だから通常t分布表には、このように「この表に書いてある数字はどこの部分の面積を指しているのか?」を示す図、または、片側検定なのか両側検定なのかという説明書きがついています。
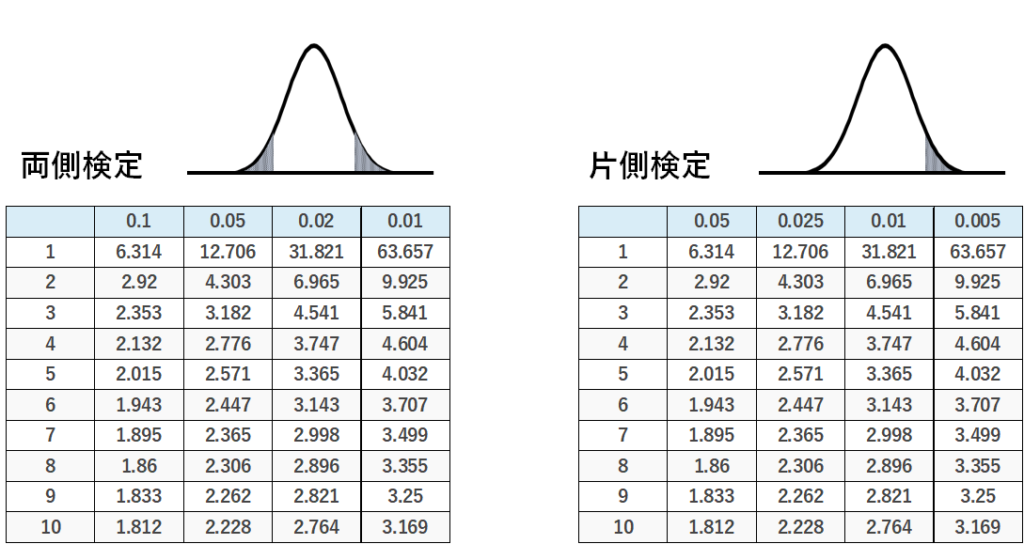
ここで、もし、片側検定をしたい時に、両側検定のt分布表しかなかったら、どうしましょうか?
大丈夫です!t分布は左右対称なので!
片側検定で値が0.05になる時のt値は、両側検定で値が0.1になる時のt値と同じになります。
同じt分布表という名前がついていても、記載してあるt値は、片側の場合のものだったり、両側検定の場合のものだったりしますので、t分布表を読み取る時には、t分布表に書いてあるのが、片側検定の時のt値なのか、両側検定の時のt値なのかを必ずチェックするようにしてくださいね。
t検定の種類
今回解説したのは、1標本t検定と呼ばれる手法ですが、t検定には主にここに示したような種類があります。

どれも、検定の手順は1標本t検定と同じで、何と何を比較するのか?というところが違います。
それによって「母分散を不偏分散に置き換える」のところのやり方、つまり、どうやって不偏分散を計算するのか?自由度は何になるのか?というところが若干異なるのですが、考え方が理解できれば、どれも難しいものではありません。
まとめ
母平均の検定をする際に、母分散が既知の場合と母分散が未知の場合で異なるのは、変換後の分布での確率変数の値を計算するための式の分母に、ある決まった値である母分散を使うか、確率変数である不偏分散を使うかです。
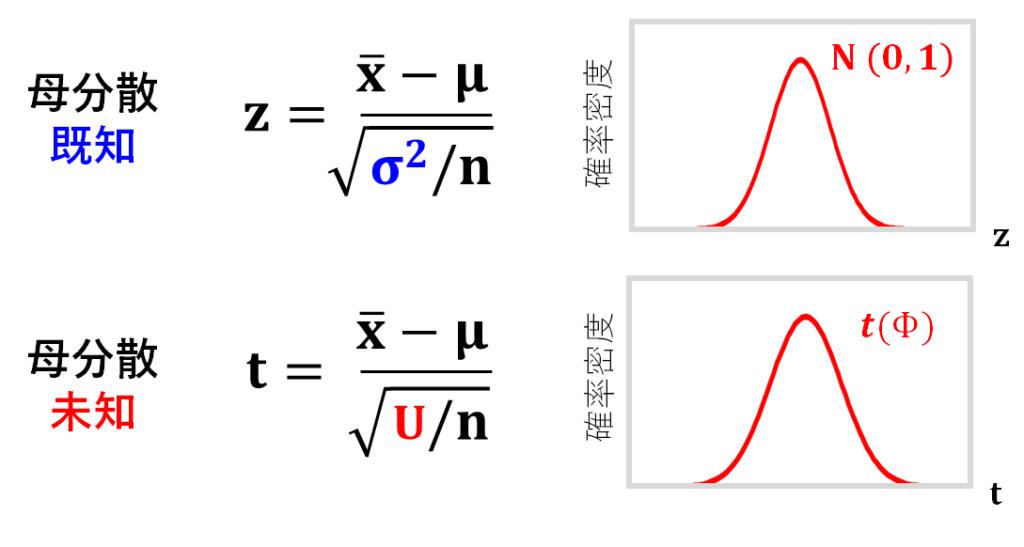
分母に不偏分散を使った場合の計算結果(t値)が従う分布は、標準正規分布ではなく、t分布です。
この記事のYouTube動画はこちら
