

対応のない2標本t検定を学ぶとき、多くの人ぶつかる壁は「計算式の意味がつかみにくい」という点なのではないかと思います。
特に、StudentとWelchのどちらを使うべきかで迷ったり、t値を計算する際に、で割るんだったか?-1で割るんだったか?と悩んだり、などがあるのではないでしょうか?
これらの混乱の多くは「式を丸暗記しようとすること」が原因であることが多いのではないかと思います。
逆に、なぜこの式になるのか、StudentとWelchにはどういう前提の違いがあるのかを理解すれば、計算そのものは驚くほどスッキリ整理できます。
この記事では、対応のない2標本t検定を理屈から理解することに焦点を当て、計算式の背景や自由度の考え方まで丁寧に解説します。
読み終える頃には、あなたの中のモヤモヤが一本の線でつながるはずです!
標本とは?
統計学における『標本』とは、母集団の分布を推測するために選ばれた一部の集団のことです。
2標本t検定とは、その名のとおり、2つの標本を使って検定する手法なので、その背後には、2つの母集団が存在しているんですね。
この2つの母集団の母平均に差があるどうかを検定するのが、2標本t検定です。
2標本t検定の説明をする前に、1標本t検定について簡単におさらいしておきましょう。
1標本t検定
1標本t検定は、標本平均がある特定の値と等しいかどうかを調べる手法です。
よって、帰無仮説は「母平均はである」になりますね。
t検定は、母分散未知の場合の母平均の検定であるわけですが、t検定を理解するには、まずは、母分散が既知だった場合からスタートすると、スムーズにいくと思います。
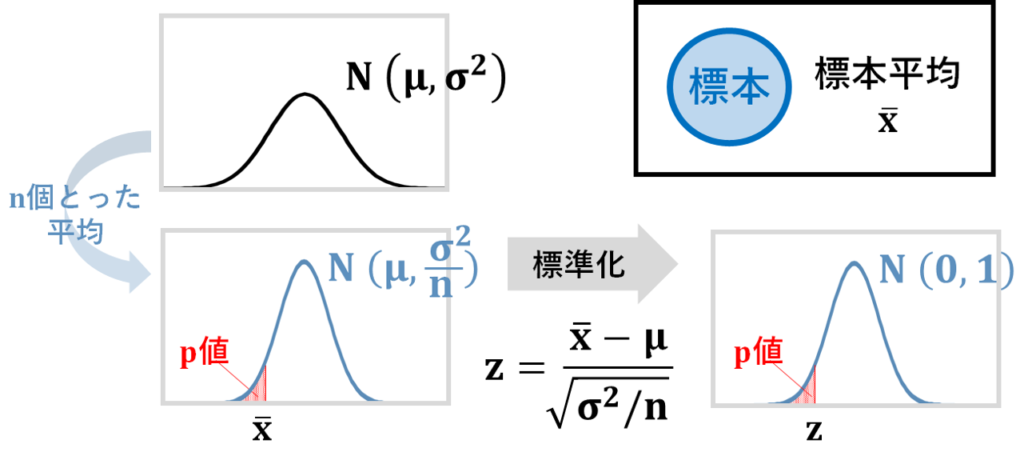
母平均、母分散の正規分布から個とったとった標本平均は、平均、分散の正規分布に従います。
これは帰無仮説が正しいと仮定したときの分布です。
実際の標本平均がだったとしたとき、この以上に極端な観測結果が得られる確率、値を求めて、値が小さい場合には、レアなことが発生したと判断するのではなく、そもそもの前提である帰無仮説が間違っていた、という風に考えます。
値を求めるために、を標準化して、スコアを求め、標準正規分布表を読み取るのが、母分散既知の場合の母平均の検定です。

t検定は、母分散未知の場合の母平均の検定であり、母分散が未知なので、の部分を標本データから計算した不偏分散に置き換えてt値を求め、t分布を読み取ります。
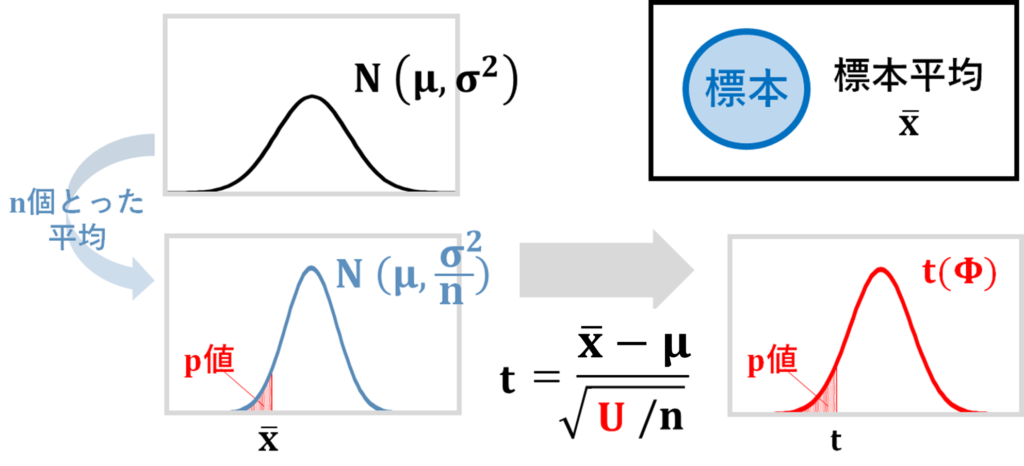
を不偏分散に置き換えた統計値が従う分布は、標準正規分布ではなくt分布になります。

2標本t検定
2標本t検定は、2つの標本データを使うので、その背景にある2つの母集団の分布の比較を行います。
が従う、平均、分散の正規母集団と、が従う、平均、分散の正規母集団の比較を行うとしましょう。
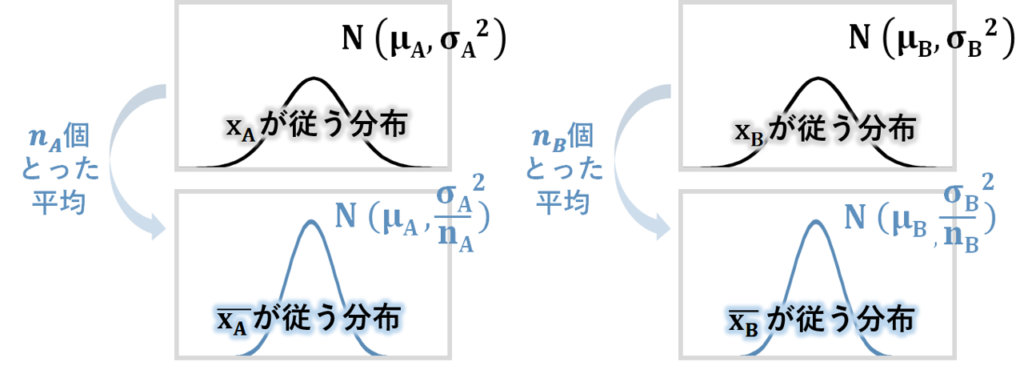
が従う分布からことった標本平均と、が従う分布からことった標本平均は、それぞれ「平均、分散の正規分布」と「平均、分散の正規分布」ですね。
ここで、帰無仮説は「母平均が同じ」なので「=」ですよね。
つまり、ー=0です。
だから、ーが従う分布を考えて、実際の標本で計算した標本平均の差が0であるかどうかをチェックすれば良いですね。
そこで、ーが従う分布を考えましょう。
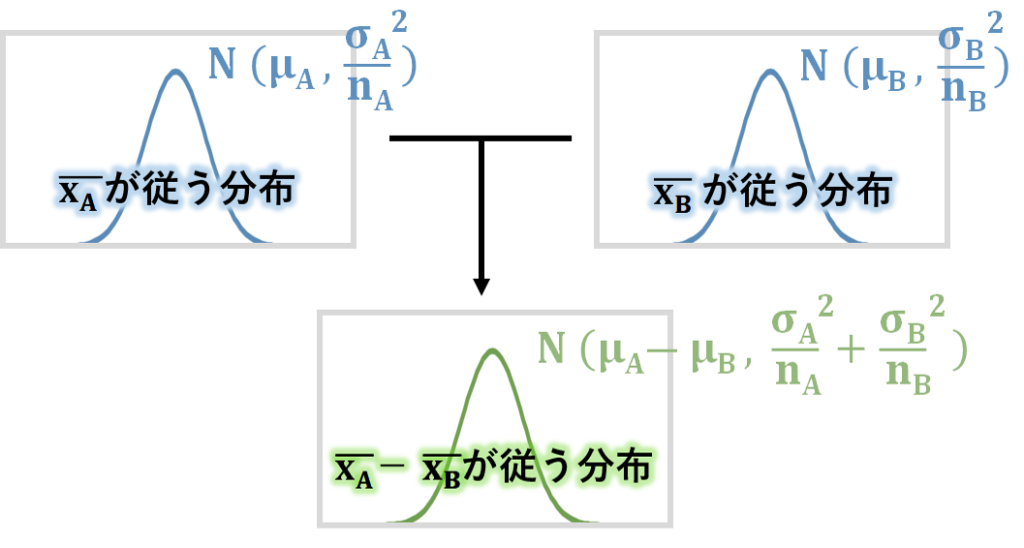
ーが従う分布の平均は、ーですよね。
ーが従う分布の分散は、分散の加法性により、+になりますね。
ーが従う分布がわかったら、次は、ここでもやはり、母分散が既知だった場合をまずは考えてみましょう。
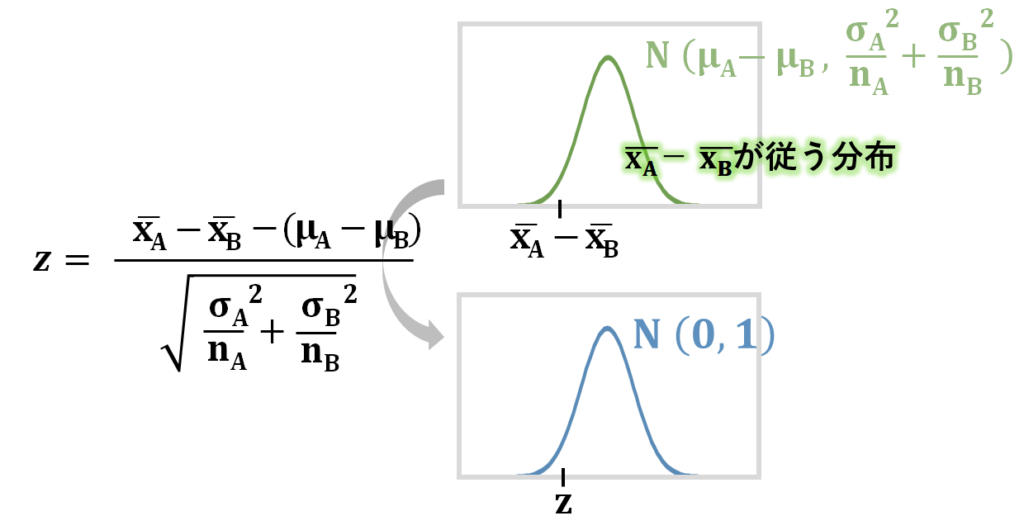
ここで、問題なのが、、、、が未知なことですよね。
とについては、帰無仮説が=なので、-は0になるので、未知のままで問題ありません。
-の部分を消すと、だいぶ計算式がスッキリしましたね。
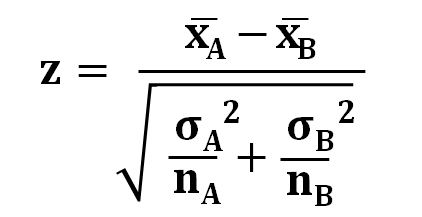
問題は、とです。
この部分についてどうするかについては、とが等しいと考えられる場合と、とが等しいかどうかがわからない場合で異なります。
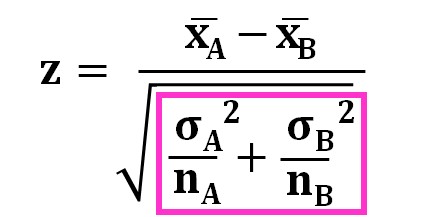
とが等しいと考えられる場合は、Studentのt検定、とが等しいかどうかわからない場合は、Welchのt検定を使います。
Studentのt検定
まずは、Studentの検定です。
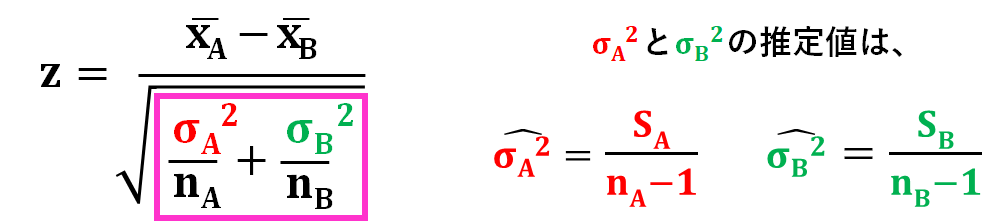
の推定値と、の推定値は、標本データを使って不偏分散(偏差平方和S÷データ数n-1)を計算すればいいですよね。
ここで、このように、の部分との部分をそれぞれの推定値で置き換えたくなると思いますが、Studentのt検定では、このようにしてははいけないんです。
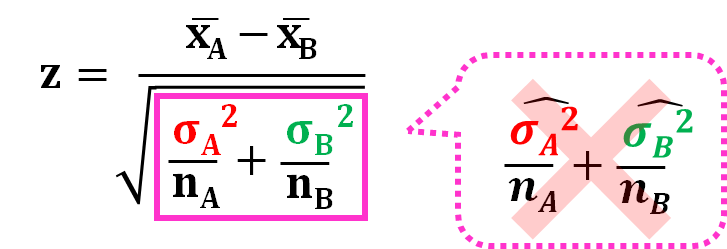
Studentのt検定では、とが等しいと考えるので、の推定値との推定値をプールした推定値を計算する必要があります。
分子の偏差平方和を足して、分母の自由度も足して、平方和の和÷自由度の和を計算したものがプールされた分散になります。
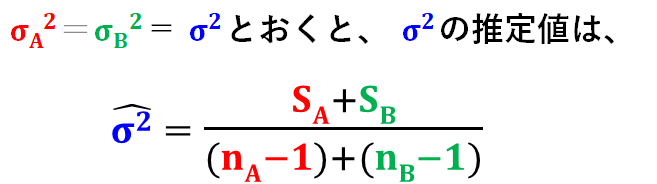
母分散が同じであると仮定できる場合には、このように、2つの不偏分散を1つにまとめることができます。
2標本のデータを1つにまとめることで、母分散の推定精度を高めることができます。
母分散をプールした分散に置き換えるので、この式で計算されるt値はt分布に従います。
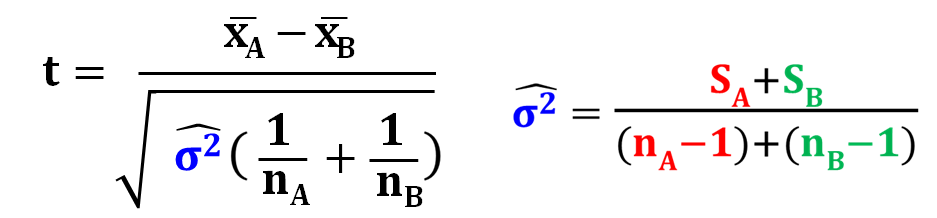
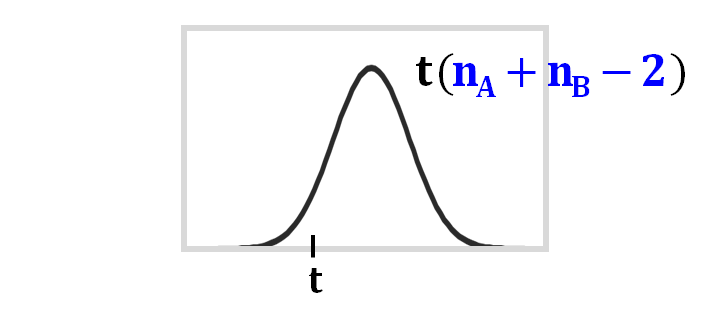
自由度は、分散の推定値の分母の部分にあたるので、プールされた分散の分母である、+-2ですね。
あとは、この計算式に実際の観測値をあてはめてt値を計算し、 それが、自由度+-2のt分布上でどこに位置するのかをチェックし、それがレアかどうかで、帰無仮説を受容するか棄却するかを判断すれば良いですね。
Welchのt検定
続いて、Welchのt検定です。
Studentのt検定では、とが等しいと考えられる場合だったので、プールした分散を使って計算しましたが、Weltchのt検定は、とが等しいかどうかわからない場合なので、分散のプールはできません。
だから、しょうがなく、とをそれぞれの推定値で置き換えます。
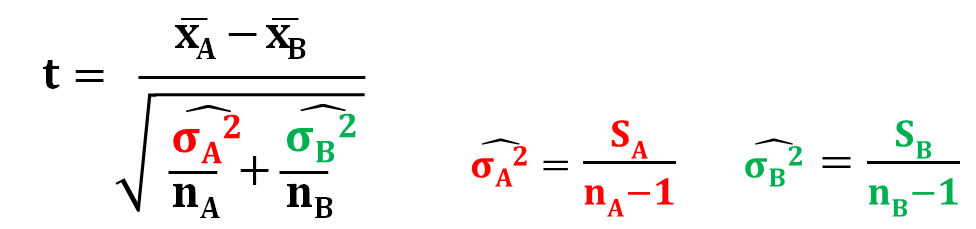
さて、この時、自由度はどうなるのか?という問題がありますよね。
自由度は、この式で求めます。
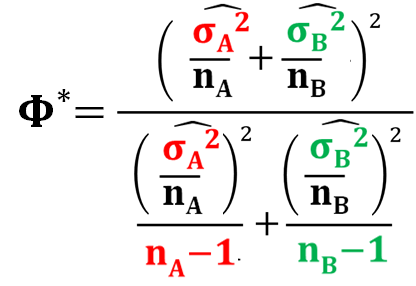
この式で計算される自由度は、等価自由度と呼ばれます。
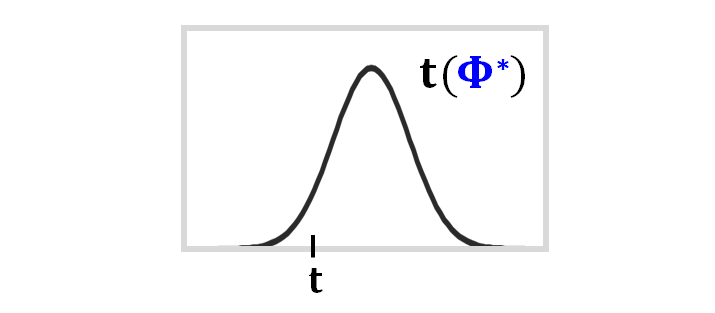
Welchのt検定では、t値と自由度をこのように計算するのですが、実はこれは近似なんです。
つまり、Welchのt検定におけるt値は、この式で計算される等価自由度のt分布に近似的に従うんです。
あとは、この計算式に実際の観測値をあてはめてt値を計算し、それが、自由度Φ*のt分布上でどこに位置するのかをチェックし、それがレアかどうかで、帰無仮説を受容するか棄却するかを判断すれば良いですね。
例題
果樹園Aのいちごは、果樹園Bのいちごと同じ重さと言えるか?
母分散は等しいと考えられるとして、有意水準5%で検定せよ。
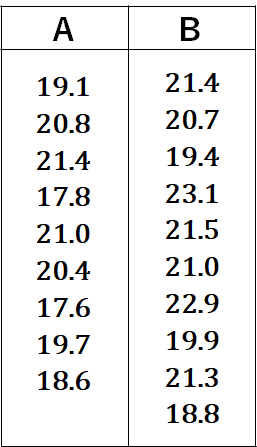
果樹園Aから9このイチゴを無作為にサンプリングして重さを計り、果樹園Bから10このイチゴを無作為にサンプリングして重さを計ったデータを使って、果樹園Aのいちごと果樹園Bのイチゴの重さが同じと言えるかどうか有意水準5%で検定します。
有意水準というのは、レアと言えるかどうかの値のしきい値のことです。
有意水準5%というのは、p値が5%よりも小さい場合にレアと言える、ということです。
果樹園Aのイチゴの重さが従う分布の母分散と果樹園Bのイチゴの重さが従う分布の母分散は等しいと考えられるとしているので、Studentのt検定を使います。
A,Bそれぞれの、平均値、偏差平方和、データ数、自由度が必要です。
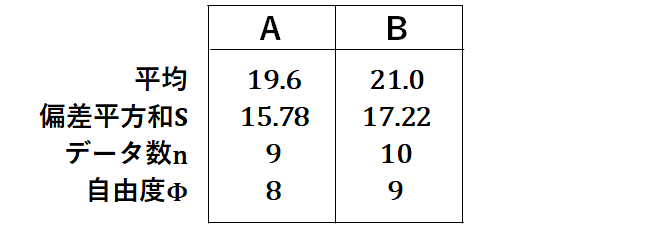
Studentのt検定を使うので、プールされた分散の計算が必要です。
AとBの偏差平方和を足して、それをAとBの自由度の和で割ります。
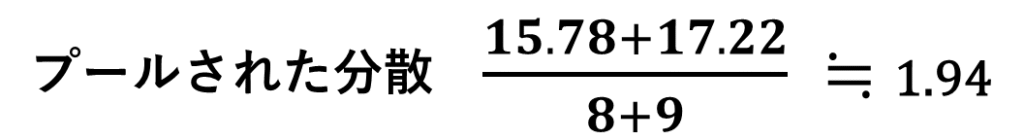
分子はAとBの平均の差、分母は、「プールされた分散÷Aのデータ数」と「プールされた分散÷Bのデータ数」の和の平方根ですね。
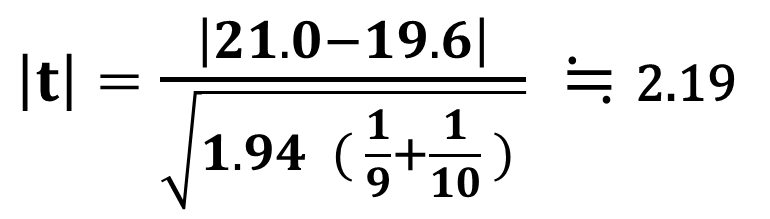
自由度が17のt分布において、𝑝値が0.05となる時のt値をt分布表から読み取ります。
「果樹園Aと果樹園Bのイチゴの重さが同じかどうか」が知りたいので、両側検定を行うことになりますので、
右の裾と左の裾、あわせて0.05になる時のt値を読み取ります。
t分布表の読み取りは割愛しますが、これは2.11になります。
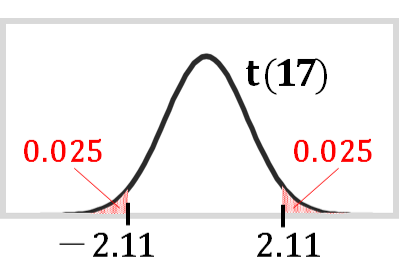
2.11よりも2.19のほうが大きいので、2.19は赤の領域に含まれます。
よって、2.19はレアと判断できるので、そもそも帰無仮説が誤っていたと考えます。
よって、帰無仮説を棄却して、対立仮説を採択します。
つまり、「果樹園Aのいちごと果樹園Bのイチゴは同じ重さとは言えない」という結論になります。
まとめ
2標本t検定とは、2つの母集団の母平均の差に関する検定です。
2つの母集団の母平均の差に関する検定を行う際に、2つの母集団の母分散が等しいと考えられる場合は、Studentのt検定、2つの母集団の母分散が等しいかどうかわからない場合は、Welchのt検定を使います。


この記事のYouTube動画はこちら
