

F検定は、2つの母集団の母分散が同じと言えるかどうかを検定する手法です。
F検定は、分散分析でも使われる手法なので、基礎をしっかりマスターしておきたいですね!

はじめに
ある製造工場において、コスト削減のために、装置の交換パーツを安価なものに変更することを検討している。
ただし、この変更により、製品の寸法への悪影響が懸念される。
そこで、現在のパーツを使って製造した製品の寸法と安価なパーツを使って製造した製品の寸法を測定し、これらのデータが得られた。

新人のAさんは、安いパーツに変更して問題ないと判断しました。
ベテランのBさんは、安いパーツに変更するべきではないと判断しました。

同じデータを使って分析したのに、この違いはなぜうまれたのでしょうか?
Aさんは、これらの寸法データを使って、t検定を行いました。

そして、現在のパーツを使って製造した時と安いパーツを使って製造した時で、寸法の平均値に差がないという結果が得られたことから、安いパーツに変更して問題ないと判断しました。
Bさんは、まずは、これらのデータの分布を箱ひげ図で確認しました。
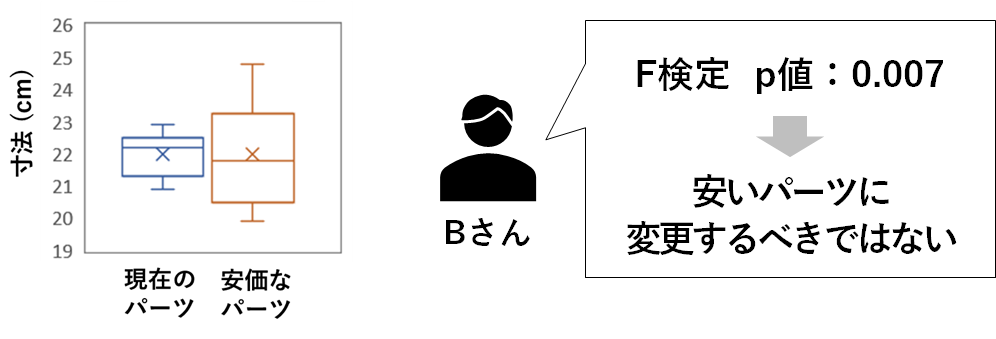
そして、×印で示されている平均値には差がありませんが、安価なパーツのほうが箱とひげが長くなっている特徴があったため、安価なパーツを使って製造すると寸法のばらつきが大きくなる可能性があると判断し、統計的にばらつきに差があるかどうかを分析するためにF検定を行いました。
そして、ばらつきに差があるという結果が得られたことから、安いパーツに変更するべきではないと判断しました。
「2群の比較を行う」という場面で、Aさんの頭に思い浮かんだのがt検定だったのでしょうね。
統計的仮説検定によって2群の比較を行う際には、2群の標本データから、背後にある2つの母集団の分布を推定し、それを比較します。
母集団の分布を表す指標には、平均と分散がありますね。
t検定で評価できるのは、2群の平均に差があるかどうか?です。
2群の分散に差があるかどうか?については、F検定によって評価できます。
F検定とは
F検定では、2群の母分散が同じと言えるかどうかを議論します。
2つの標本データから、母集団の分布を推定し、それを比較するわけですが、このとき、母平均については、標本平均が良い推定量となり、母分散については不偏分散が良い推定量となります。
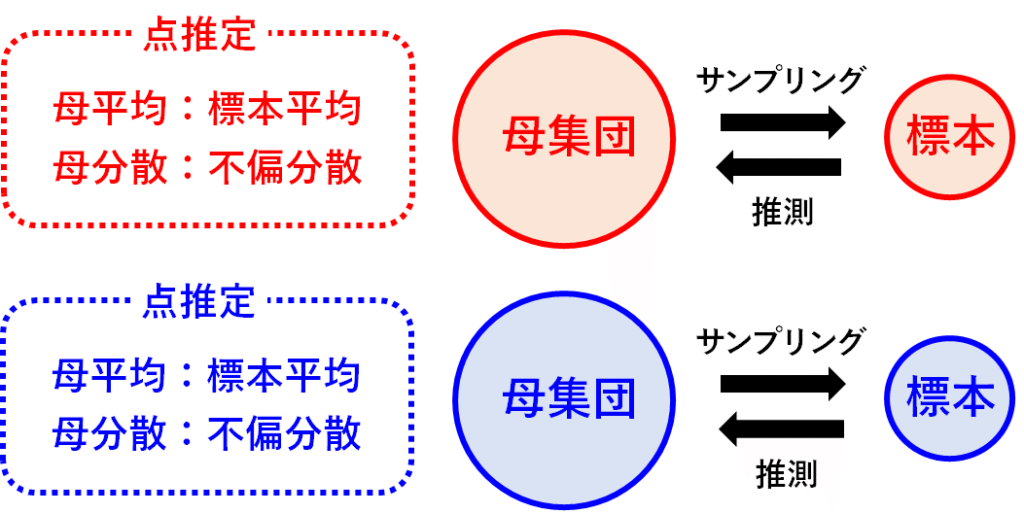
母平均を比較するのがt検定、母分散を比較するのがF検定です。
t検定で母平均を比較する際には、標本平均の“差”が従う分布をもとに検定を行いますが、F検定で母分散を比較する際には、不偏分散の“比”が従う分布をもとに検定を行います。
F値はなぜ“比”なのか
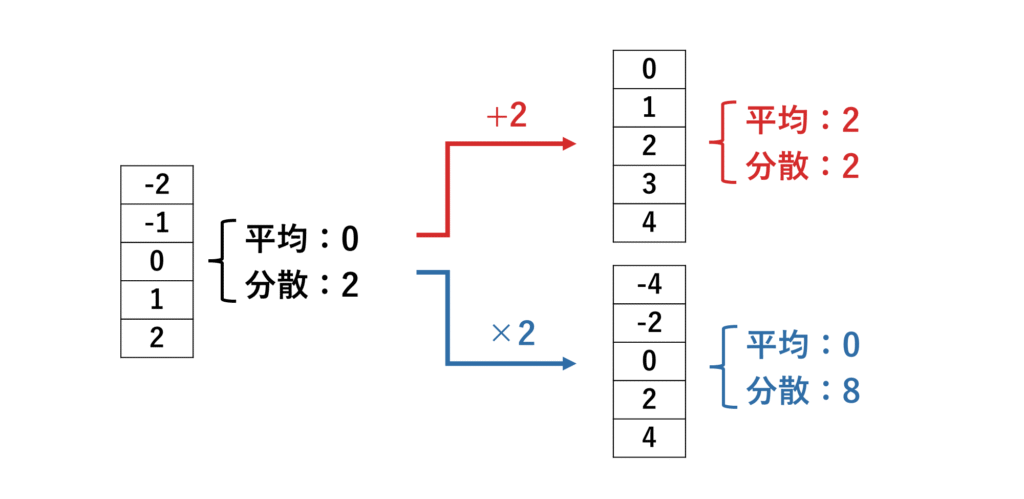
例えば、平均が0のこれらのデータがあったとします。
これらに一律2足したとき、平均は+2されますが、分散は変わりませんね。
これらに2をかけた場合は、平均は変わらず、分散は4倍になりますね。
確率変数でも同じことで、例えば、平均が0のある正規分布に2足した時、平均は+2されて、分散は変わりません。
2をかけた場合は、平均は変わらず、分散は4倍になります。
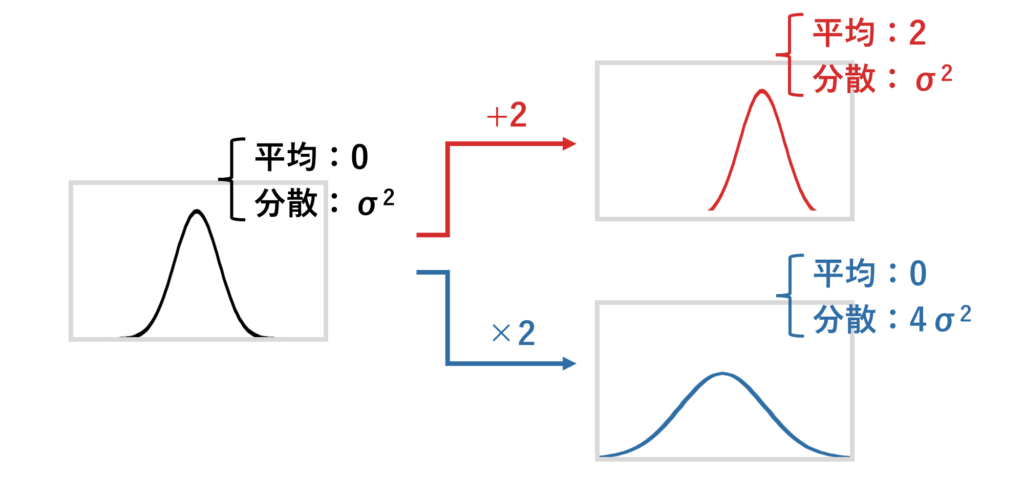
平均の違いを議論したい時は”差”に着目し、分散の違いを議論したい時は”比”に着目するんですね!
ということで、F検定では、2つの母分散の点推定量の比(つまり不偏分散の比)が従う分布をもとに検定を行います。
F分布
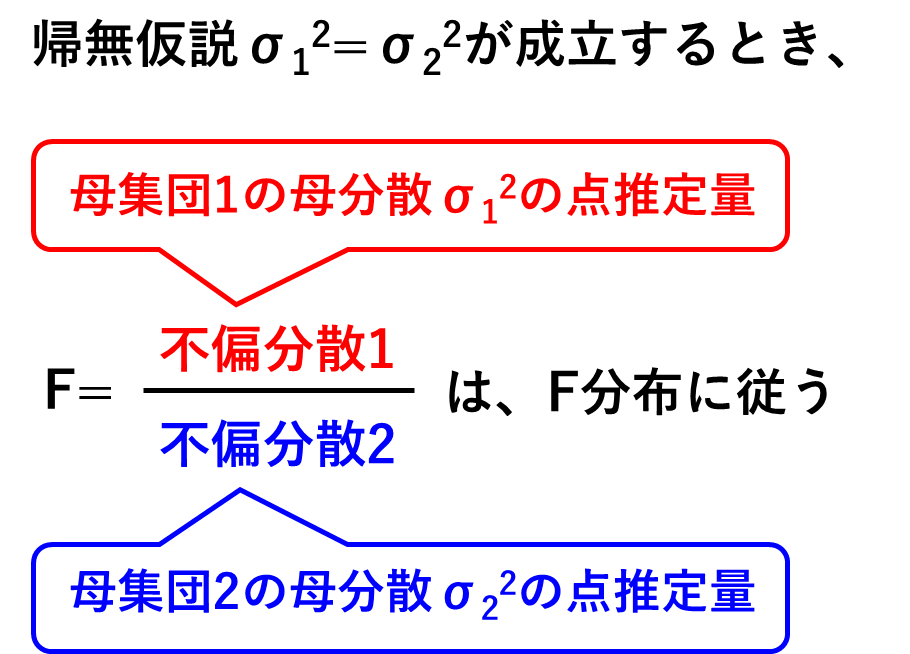
2群の母分散に差があるかどうかを知りたい時は、2つの母集団の母分散σ12とσ22が等しいという帰無仮説を設定します。
2群から抽出した標本のサイズが無限大(つまり自由度が無限大)の時は、母分散の推定値は母分散と一致するので、帰無仮説が成立するとき、不偏分散の比は必ず1になりますよね。
しかし、実際には、少数の標本データで母分散を点推定することになりますので、その推定値は母分散とは一致しません。
母分散は、ある決まった1つの値であるわけですが、不偏分散の計算結果は、標本が異なれば異なりますよね。
つまり、不偏分散の計算結果は、母分散からずれるということです。
だから、帰無仮説が成立している場合であっても、F値はぴったり1にはならずに、1からずれた値になることもあり得ます。
ということは、F値は確率的に変動する統計量であるということです。
であれば、何らかの分布に従っているはずで、その分布がF分布というわけです。
F分布の形状は、自由度に依存します。
自由度とは、不偏分散の計算式中の分母のことです。
不偏分散の計算式はこれで、自由度は”n-1″の部分ですね。
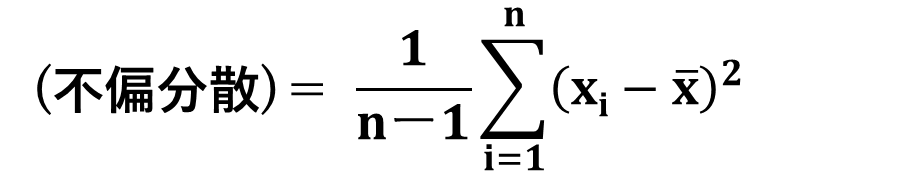
F値の計算式中には不偏分散が2つあるので、自由度が2つあります。
だから、F分布の形状は2つの自由度によって決まります。
これは、自由度が大きい場合のF分布と、自由度が小さい場合のF分布です。
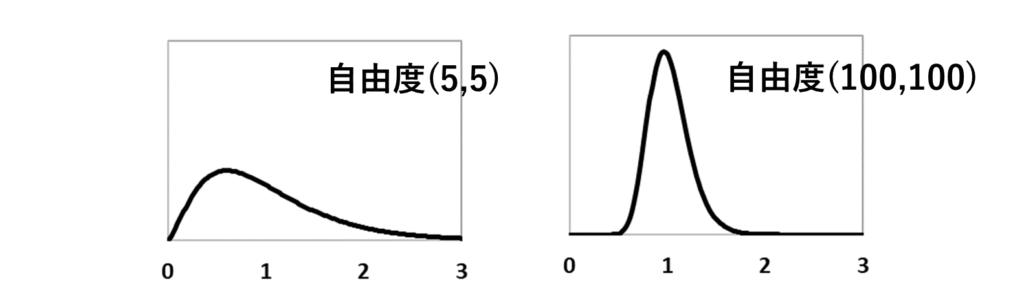
自由度が大きい場合はシャープですが、自由度が小さい場合はブロードですね。
帰無仮説が成立している時、F値の計算式中の2つの不偏分散の計算における自由度が大きければ、あまり1からずれることはないが、自由度が小さくなると、1からかなりずれた値をとる可能性も出てくる、ということです。
F検定
さて、帰無仮説が成立する場合にF値が従う分布がわかれば、あとはz検定やt検定と同じように、実際のデータでF値を計算した結果が、どのくらい起こりにくいのかをチェックすれば良いですよね。
最初の例題を用いて、実際にF検定をしてみましょう。
ある製造工場において、コスト削減のために、装置の交換パーツを安価なものに変更することを検討している。
ただし、この変更により、製品の寸法への悪影響が懸念される。
そこで、現在のパーツを使って製造した製品の寸法と安価なパーツを使って製造した製品の寸法を測定し、これらのデータが得られた。
現在のパーツを使用した場合の寸法が従う分布を、平均μ1、分散σ12の正規分布、安価なパーツを使用した場合の寸法が従う分布を、平均μ2、分散σ22の正規母分布だとします。

帰無仮説「2つの標本をとってきた元の母集団の母分散が等しい(つまり、σ12=σ22)」が成立する時、この式で計算されるF値はF分布に従います。
不偏分散1(σ12の点推定量)は、現在のパーツの11のデータを使って不偏分散を計算し0.478となります。
不偏分散2(σ22の点推定量)は、安価なパーツの9このデータを使って不偏分散を計算し2.6825となります。
ここで、F値は『不偏分散÷不偏分散』なのですが、どちらの不偏分散を分子にもってきて、どちらの不偏分散を分母にもってきたらよいでしょうか?
この式でF値を計算する時には、「分子の不偏分散は、母分散が『大きい』と仮定しているほうにする」というルールがあります。
これはなぜかと言うと、F分布の確率が示されているF分布表には、右側の裾(赤の部分)の面積が、0.05であったり0.01であったり、になる時のF値が記されているからです。
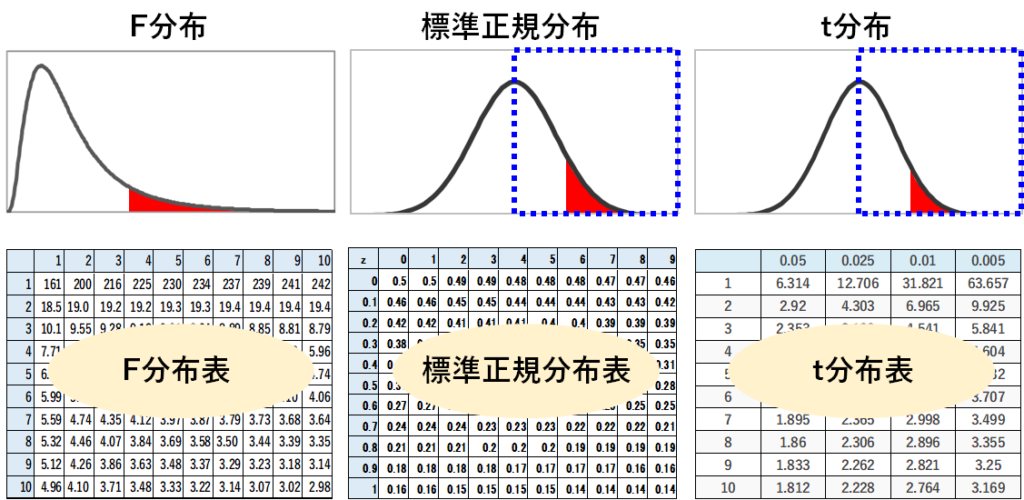
正規分布やt分布は左右対称なので、比較対象の大小関係がどうであったとしても検定を行うことができます。
F分布は左右非対称なので、それができません。
分子のほうが大きい場合には、右側の裾の面積を議論し、分母のほうが大きい場合には、左側の裾の面積を議論するわけですが、左側の裾の面積に着目したF分布表というのは、通常は使われません。
Bさんは、現在のパーツを使用して生産した場合よりも、安価なパーツを使用して生産した場合のほうが、寸法のばらつきが大きい可能性があると思いF検定をしたわけなので、大きいと仮定しているほうのσ22の点推定量が分子、σ12の点推定量が分母になるわけですね。
F分布は自由度によって変わるのでしたね。
分子の不偏分散の計算に使った自由度のことを第一自由度、分母の不偏分散の計算に使った自由度のことを第二自由度と言います。
ここでは、第一自由度が8、第二自由度が10になりますね。
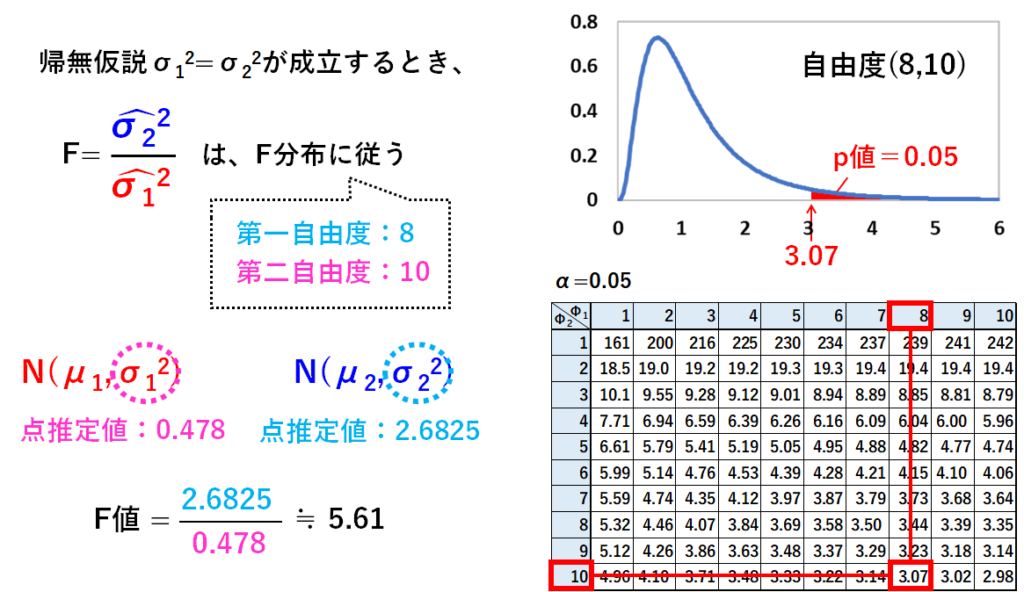
実際のデータで計算したF値は、2.6825÷0.478を計算し、約5.61です。
1から離れているので、発生確率は低そうですが、これがレアなのかどうかを確認してみましょう。
レアかどうかのしきい値(これを有意水準と言います)は、一般的には0.05が用いられることが多いので、ここでも0.05だとしましょう。
p値が0.05になる時のF値をF分布表から読み取り、その値よりも実際の標本データで計算したF値のほうが大きい場合は、帰無仮説の矛盾が主張できるので、帰無仮説を棄却することになります。
ここに示したのは、p値が0.05の時のF分布表です。
F分布表は、横に第一自由度、縦に第二自由度が書いてあり、それがクロスするところに、p値がある値(ここでは0.05)になる場合のF値が書いてあります。
第一自由度が8で第二自由度が10なので、3.07以上となる確率(図中の赤の部分の面積)が0.05ということですね。
実際の標本データでの計算値は5.61なので、3.07よりも大きいです。
これは、もし帰無仮説が正しいなら、5.61という値が得られる確率はかなり低い、ということを示しています。
つまり、帰無仮説の矛盾を主張できるので、帰無仮説を棄却します。
結論としては、σ22のほうがσ12よりも大きいと言えそう、つまり、「安価なパーツを使用して生産した製品の寸法ばらつきのほうが大きいと言えそう」となります。
まとめ
F検定は、2つの母集団の母分散が等しいと言えるかどうかを検定する手法です。

2つの母分散の点推定量(不偏分散)の比で計算されるF値は、第一自由度が”分子の不偏分散の計算に用いた自由度”、第二自由度が”分母の不偏分散の計算に用いた自由度”のF分布に従います。
F分布は左右非対称なので、通常は、大きいことを証明したいほうを分子にします。
検定の進め方はt検定をはじめとした各種検定と同じです。
帰無仮説が正しい場合にF値が従う分布を考えて、実際の観測値で計算されたF値が得られることがレアである場合は、実際の観測値と帰無仮説に矛盾があることになりますので、帰無仮説が誤っていたという風に考えます。
この記事のYouTube動画はこちら
