

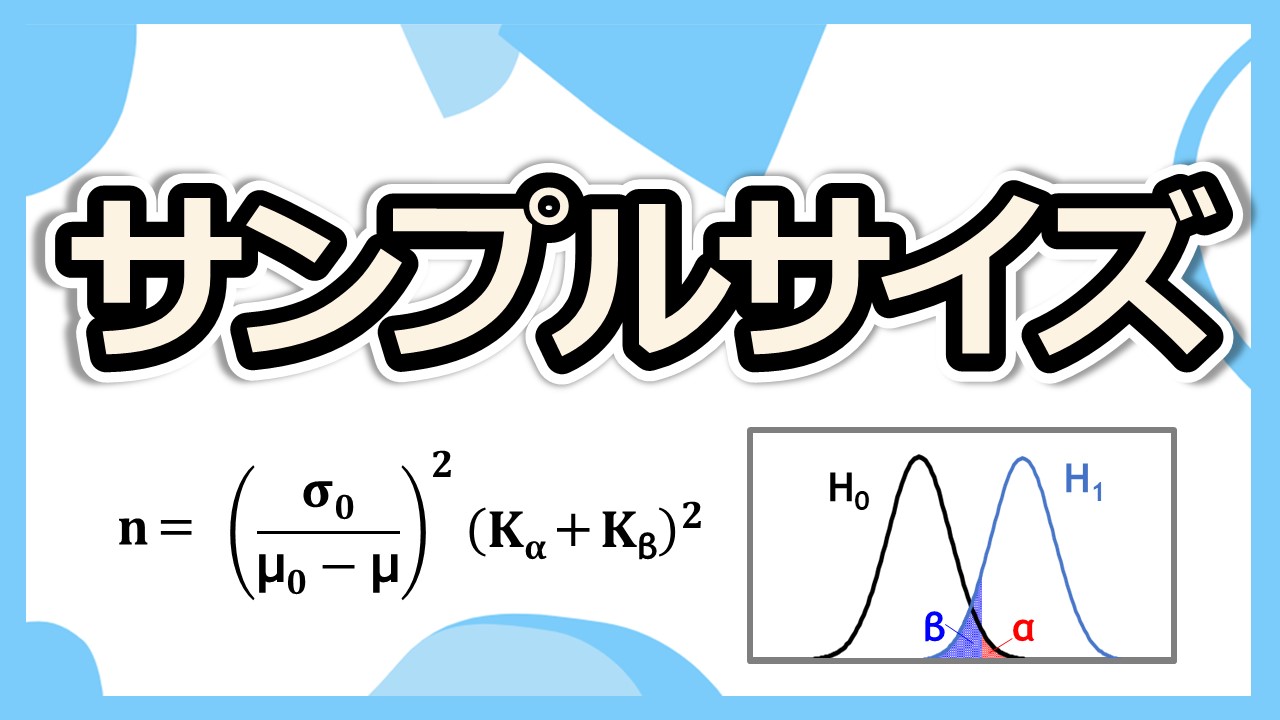
統計分析を行ううえで欠かせない概念のひとつが『サンプルサイズ』です。
どれだけデータを集めるべきか──これは統計分析を行う際に必ず直面する重要なテーマです。
サンプルサイズは、分析結果の精度や信頼性を大きく左右するため、適切な数を設定できるかどうかが結論の妥当性に直結します。
サンプルサイズは「多ければ良い」という単純なものではありません。
少なすぎれば結果が不安定になり、誤った結論につながるリスクが高まります。
一方で、必要以上に集めても、分析の目的に対して過剰なデータとなり、調査や実験の負担が増えるだけで本質的なメリットは得られません。
この記事では、サンプルサイズの基本的な考え方から、適切なサンプルサイズを求めるための要素、よくある誤解や注意点まで整理して解説します。
統計的仮説検定の基本的な考え方に触れたことがあれば、必要に応じて関連記事を確認しながら初学者でも十分に理解できる内容です。
母分散既知の場合の母平均の検定がベースになりますので、不安な方は、先にこちらの基礎を軽く復習しておくと安心です。

この記事を読むと次のことがわかります。
- サンプルサイズとは何か
- サンプルサイズが結果の信頼性に与える影響
- 必要なサンプル数を決める要素
- サンプルサイズが不足したときに起こる問題
- 実務に役立つサンプルサイズの考え方
統計検定・QC検定・データ分析の実務にも役立つ内容です。
例題
ある製造工場において、製品Aの特性aが 母平均 µ0=58、母分散σ02=9 であることがわかっている。
特性aは高いほど優れており、特性aを改善するために製造条件変更を検討している。
製造条件変更の効果を判断するために、試験を行い、試作品の特性aの測定結果として下記のデータを得た。
データ:58.3, 63.1, 57.9, 60.7
製造条件変更によって、特性aが高くなったかどうかを、有意水準5%で検定したい。
※特性aは正規分布に従っているとし、製造条件変更前後で母分散は変化しないものとする。
条件変更後の母平均をµとすると、帰無仮説は、µ0=µ、対立仮説は、µ>µ0、となります。
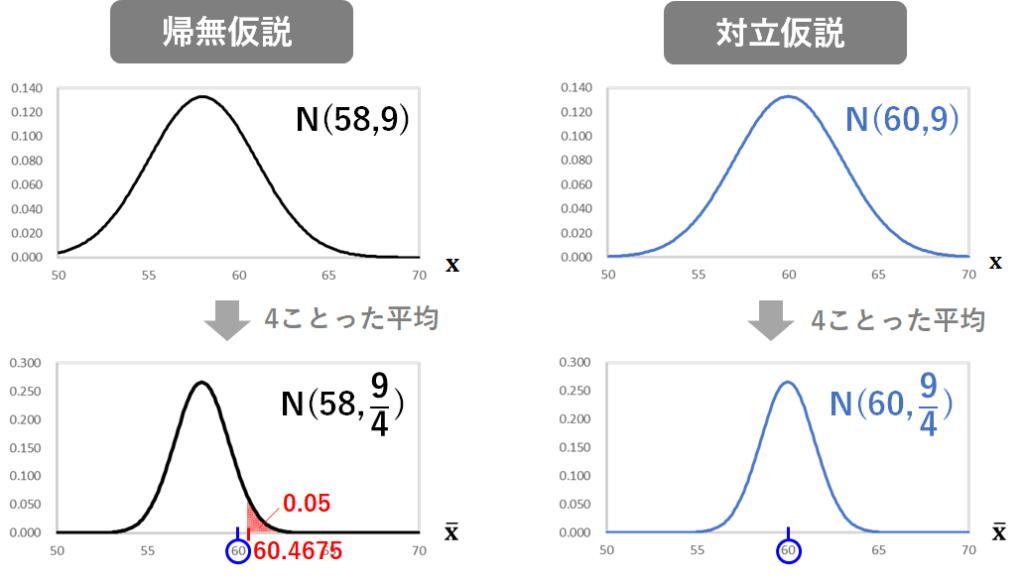
帰無仮説が正しいと仮定したときの条件変更後の試作品の特性aの母集団は、母平均58、母分散4の正規分布なので、ここから4つサンプリングした標本平均が従う分布は、母平均が元の分布の母平均 58、母分散 (元の分布の母分散9÷サンプルサイズ4)の正規分布になります。
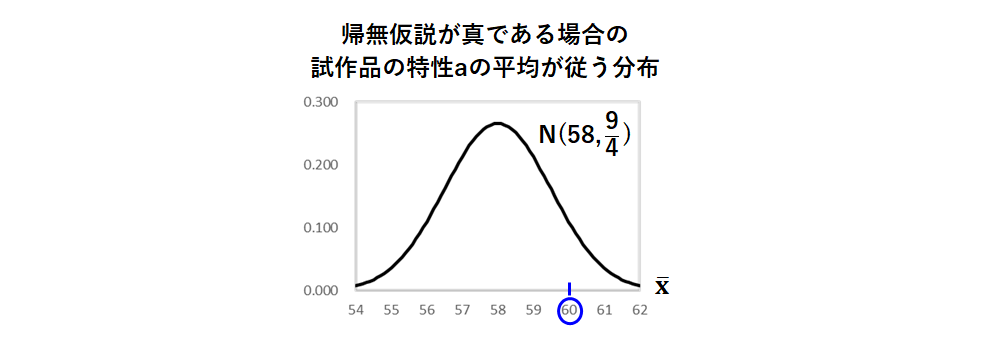
実際の4つの試作品の特性aの平均は、(58.3+63.1+57.9+60.7)÷4=60となります。
60が観測される確率は低くはなさそうですね。
この分布を標準化しましょう。
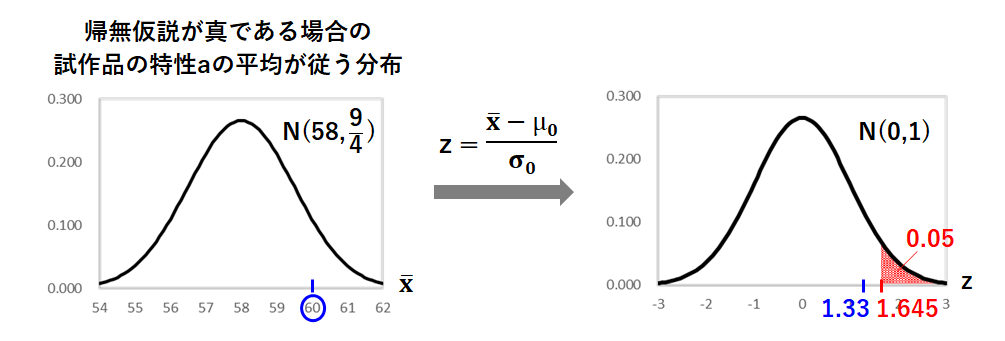
平均58、分散 の正規分布上での60は、標準正規分布上では1.33に相当します。
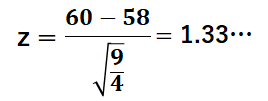
赤の部分の面積が5%の時のz値は、標準正規分布表を読み取って1.645であり、1.33は1.645よりも小さいため、有意水準5%で、製造条件変更によって特性aは高くなったとは言えない、という結果になりますね。
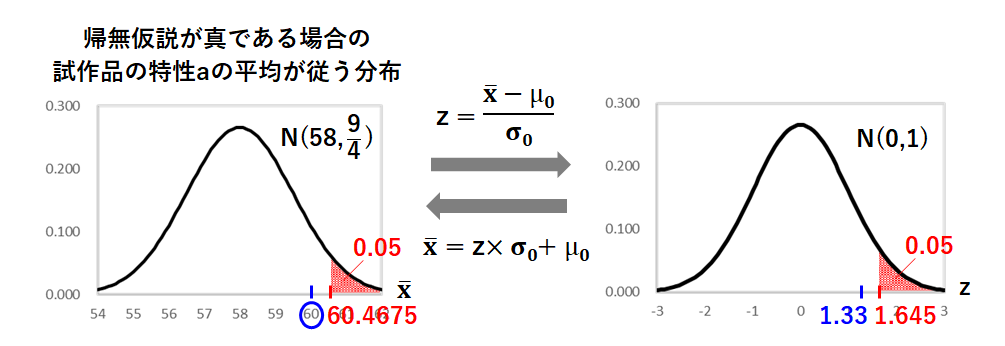
または、標準化後の赤の部分の面積が5%の時の値が1.645なのであれば、標準化前の赤の部分の面積が5%の時の値は、1.645×+58=60.4675であり、60は60.4675よりも小さいので、有意水準5%で、製造条件変更によって特性aは高くなったとは言えない、という考え方もできますね。
ここで、固有技術的には、特性aが元の58から60に変化すれば、特性aは改善した、という風に考えられるとしましょう。
固有技術的には、改善したと言えると考えられるのに、統計的仮説検定では改善したとは言えないという結果になっているわけです。
なぜこのようなことになっているのかと言うと、統計的仮説検定で帰無仮説が棄却されなかった場合というのは、
- 実際に意味のある差がなかった
- 実際には意味のある差があったがサンプルサイズ不足などが原因で帰無仮説が棄却されなかった
この2つの場合が考えられるからです。
このケースは、❷のパターンが相当していそう、つまり、4つの試作品のデータを使って統計的仮説検定を行いましたが、サンプルサイズが4では足りていなかった可能性があるということです。
検出力
統計的仮説検定では、仮説が正しいかどうかを統計的に判断するわけですが、その判断が100%正しいことはなく、判断と事実が異なる可能性が常にあります。
統計的仮説検定で起こりうるのは、この4つのパターンです。
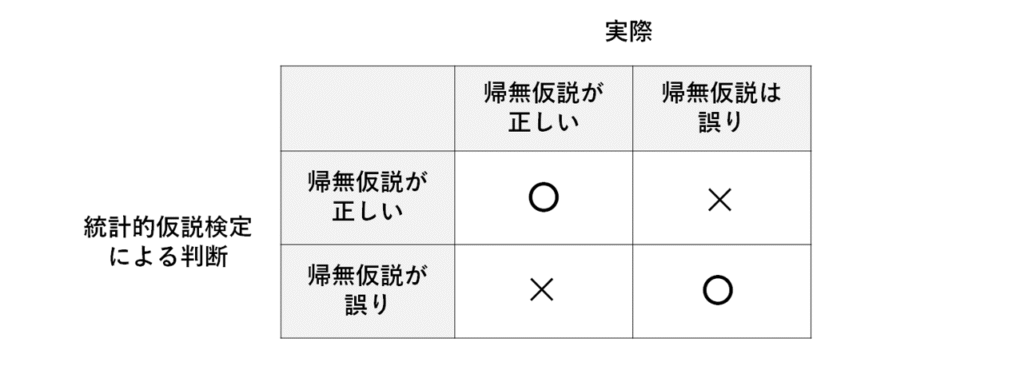
帰無仮説が正しい時に、帰無仮説が正しいと判断する場合と帰無仮説が正しくないと判断する場合、
帰無仮説が正しくない時に、帰無仮説が正しいと判断する場合と帰無仮説が正しくないと判断する場合、
この4つのパターンが考えられますよね。
この中で、判断が合っているのは〇の2つ、判断が間違っているのはこの×の2つですね。
ここで、この×の2つの判断間違いは、間違い方の質が異なります。
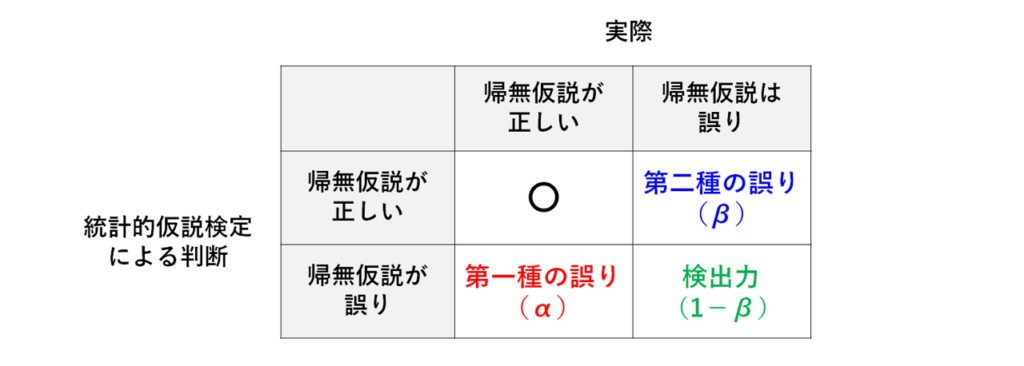
左下は、帰無仮説が正しいにも関わらず、帰無仮説が誤っていると判断してしまっています。
これを、第一種の誤りと言い、この発生確率を通常αで表現します。
右上は、帰無仮説が誤っているにも関わらず、帰無仮説が正しいと判断してしまっています。
これを、第二種の誤りと言い、この発生確率を通常βで表現します。
統計的仮説検定では、通常、帰無仮説が誤っていることを主張することを目的としています。
つまり、右側の列のほうを主張したいわけで、それを正しく判断できる確率は、1-βとなりますよね。
この1-βは、実際に帰無仮説が誤っている場合に、帰無仮説が誤っていると正しく統計的に判断できる確率のことであり、これを『検出力』と言います。
さきほどの例では、帰無仮説が誤っているにも関わらず、帰無仮説を棄却できなかった(帰無仮説が正しいと判断された)わけですが、その原因としてよくあるのが、「サンプルサイズが小さくて、第二種の誤りベータが高かった、つまり検出力が低かった」というケースです。
よって、統計的仮説検定で帰無仮説が棄却されなかった場合には、十分な検出力があったのかどうかを確認した上で、最終的な判断をする必要があります。
サンプルサイズ
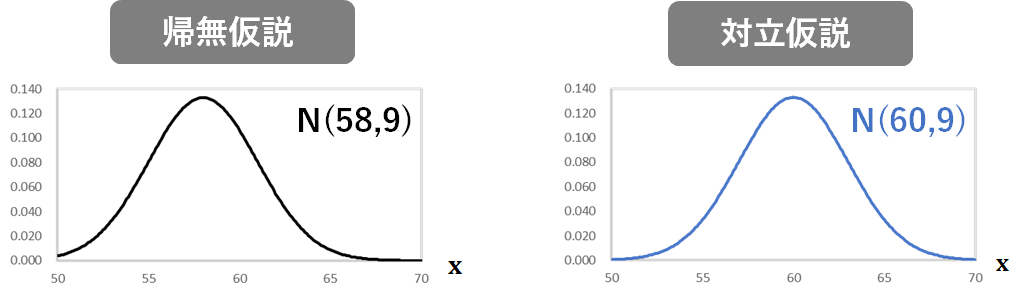
さきほどの例では、帰無仮説が成立している場合、つまり、製造条件変更前後で特性aに変化がない場合に、条件変更後の特性aが従う分布は、平均58、分散9の正規分布ですね。
対立仮説が成立している場合(つまり、条件変更後に特性aが高くなっている場合)の、条件変更後の特性aが従う分布は未知なわけですが、固有技術的には、特性aが60以上であれば「特性aは改善した」と考えられる状況であったので、平均は60以上であるはずですよね。
母分散については、条件変更前後で変化しないものとするという前提条件があるので、9であると考えることができます。
固有技術的に意味があると考えられる最も小さい差は、条件変更によって58が60になった場合なので、ここではこの最小の差が発生している場合の分布である、平均60,分散9の正規分布を一旦示すことにします。
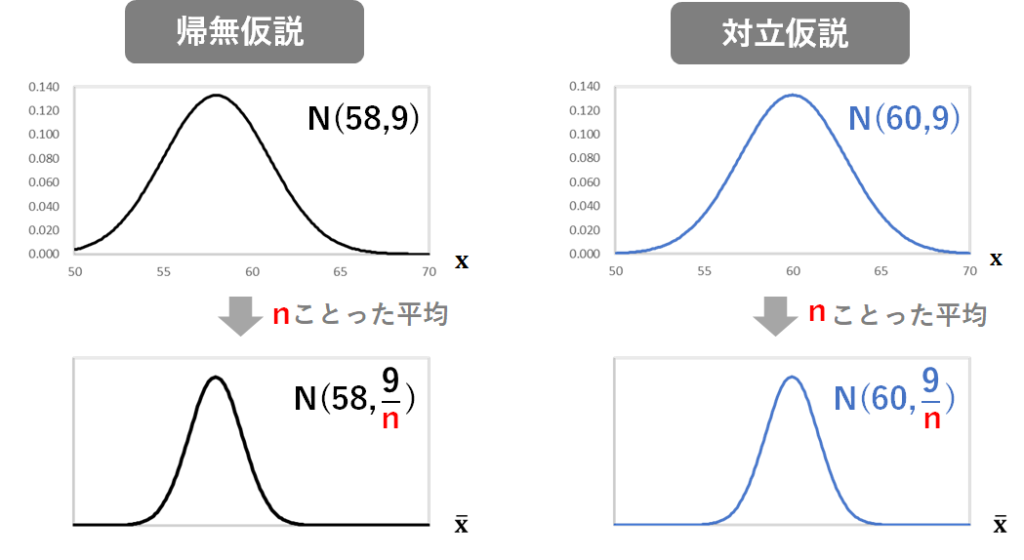
試作品を4つつくって特性aを測定したとき、その平均が従う分布は、帰無仮説が成立している時については平均58、分散 の正規分布、対立仮説が成立している時については、平均60以上、分散 の正規分布となります。
帰無仮説が成立している場合、赤の部分の面積が0.05となるときの値は60.4675でしたね。
今回、帰無仮説は棄却されなかったわけですが、それは、4つの試作品の特性aの平均が60であり、60.4675よりも小さいからですよね。
言い換えると、「帰無仮説が成立していると仮定したときに、60という値が得られる確率は低くはないので、試作品の測定結果は、帰無仮説が正しいと仮定したときの分布からサンプリングされたものであると考えられるということです。
ここで、本当に帰無仮説が正しいのであれば、「対立仮説が成立していると仮定したときに、60という値が得られる確率」は低いはずですよね。
そうでないと、帰無仮説も正しそう、対立仮説も正しそう、というどっちつかずになってしまいますもんね。
しかし、ここでは60という値が観測される確率は低くはなっておらず、試作品の測定結果は、対立仮説が正しいと仮定したときの分布からサンプリングされたのもであるという仮説を否定できるような結果にはなっていませんよね。
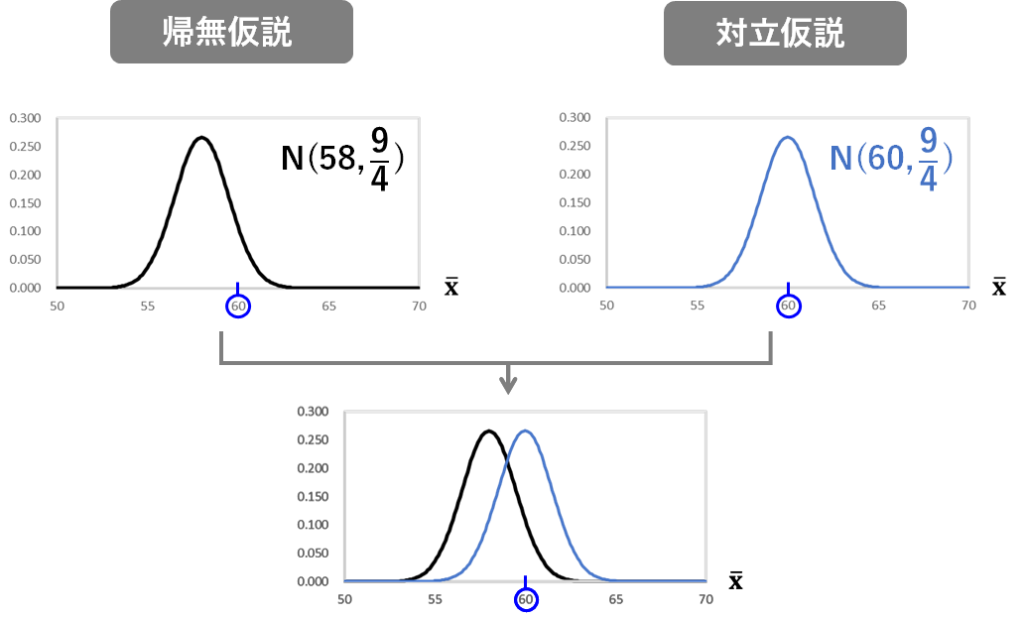
つまり、この2つの分布を重ねた時に、このように重なりが大きくて、実際の観測結果が、この重なっている領域にあった場合には、帰無仮説が正しいのか対立仮説が正しいのかを判断することが難しく、統計的には帰無仮説が棄却されなかったとしても(つまり、帰無仮説が成立している可能性が高かったとしても)、それはイコール対立仮説が成立している可能性が低いということにはならないということです。
この重なりを少なくするには、サンプルサイズを大きくすればよいですね。
なぜなら、標本平均が従う分布の母分散は「元の分布の母分散÷サンプルサイズ」となるためです。
では、帰無仮説が棄却されなかった時に、対立仮説が成立している可能性を低くするためには、いったいサンプルサイズがいくつであればよかったのでしょうか?
サンプルサイズをnとすると、帰無仮説が成立している場合と対立仮説が成立している場合の標本平均が従う分布はこのようになります。
この標本平均が従う分布を標準化して、標準正規分布表から、赤の部分の面積が0.05になるときの値を読み取り、1.645とわかり、そして、元の分布上での、赤の部分の面積が0.05になる時の値が、58+1.645× だとわかるのでしたよね。
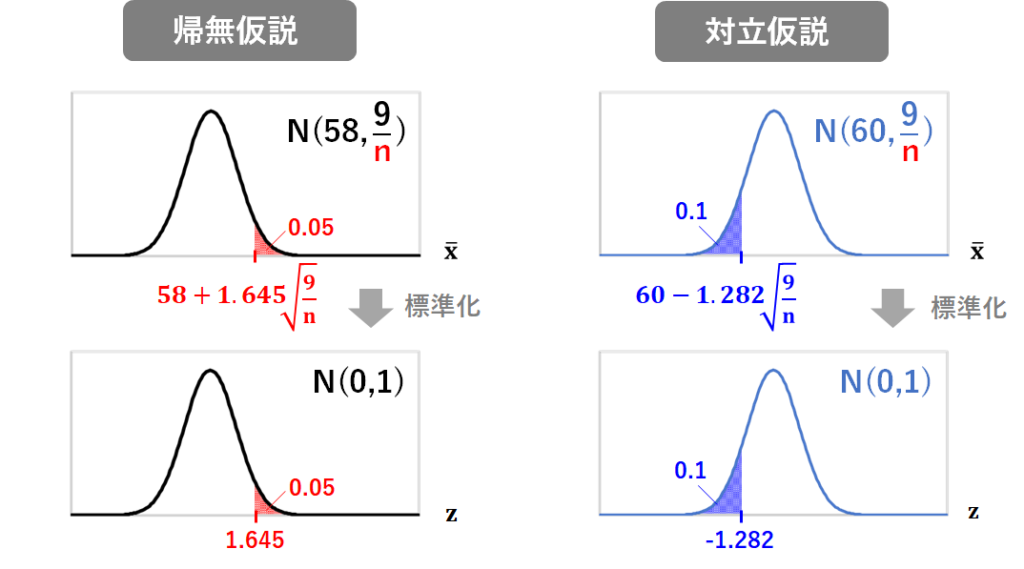
ここで、対立仮説が正しいと仮定したときの、58+1.645× が得られる確率が低くあってほしいわけです。
もしそうであれば、帰無仮説が正しいと仮定したときのある値が得られる確率が低くない&対立仮説が正しいと仮定したときのある値が得られる確率が低い、となって、違和感がない結論になってくれるからです。
とはいえ、統計的仮説検定では、判断と事実が異なる可能性が常にあり、確率的に判断するので、この値が得られる確率をどのくらい低い確率に設定するのか、ということを決める必要があります。
通常、この確率(青の部分の面積)は、0.1または0.2に設定するのが一般的です。
今回は、0.1に設定することにしましょう(つまり、検出力を 1-0.1=0.9 に設定するということですね)。
標準正規分布上で青の部分の面積が0.1になるときの値は標準正規分布表を読み取ってー1.282とわかるので、元の分布での青の部分の面積が0.1になるときの値は、60-1.282× となります。
この2つがイコールになるサンプルサイズnであれば、2つの分布を重ね合わせた時に、重なりが大きすぎることはなくなりますよね。
計算してみましょう。
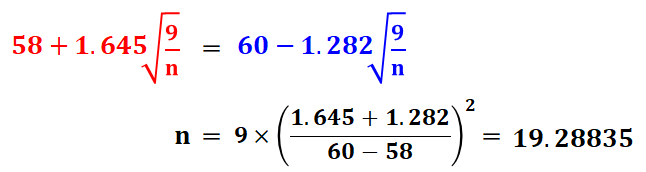
これは、αが0.05以下、βが0.1以下となる最低必要数を示しているので、最適サンプルサイズnは20となります。
つまり、特性aが60よりも高い時に有意な差があると判断したいの時の、最適サンプルサイズは20ということです。
さきほどの例では、サンプルサイズが4だったので、サンプルサイズが小さかったために帰無仮説が棄却されなかった可能性があるということになります。
このように、統計的仮説検定を行う場合には、「対立仮説が真である時に、それを正しく検出できること」が重要であり、そのためには、技術的に検出したい意味のある差を明らかにしたうえで、必要なサンプルサイズを検討することが重要です。
まとめ
この記事では、サンプルサイズの基本的な考え方と、サンプル数が分析結果に与える影響について整理しました。
- サンプルサイズは結果の精度や信頼性を左右する重要な要素
- サンプルサイズが小さいと、効果があっても検出できず帰無仮説が棄却されないことがある(検出力不足)
- 帰無仮説が棄却されない=差がない、ではなく「差を検出できなかった」可能性がある
- 検出したい差を明確にし、その差を捉えるために必要なサンプルサイズを設定することが重要
サンプルサイズは「多ければ良い」「とりあえず集めれば良い」という単純なものではなく、 どの程度の差を、どれくらいの確率で検出したいのか という目的に応じて設計する必要があります。
