


回帰分析には、モデルの当てはまりを評価するための指標がいくつかあります。
その中でも 「決定係数 R²」 は、最もよく使われる基本的な指標のひとつです。
R² は 0〜1の範囲をとり、値が大きいほどモデルの説明力が高いとされます。
しかし、実際には 0 を下回ることがある など、初心者がつまずきやすいポイントも多く、正しく理解しておくことが大切です。
この記事では、決定係数 R²の意味や計算の考え方、0〜1の範囲の理由、そして0を下回るケースについて、初心者でも理解しやすいように図解を交えて丁寧に解説します。
なお、この記事では決定係数 R² の意味と考え方に焦点を当てて解説しているため、必要以上に専門的な数式に踏み込まない構成になっており、統計に詳しくなくてもスムーズに理解できる内容になっています。
この記事を読むと次のことがわかります。
- 決定係数 R² の意味と役割
- R² が 0〜1 の範囲をとる理由
- R² が 0 を下回るケースが生じる仕組み
- 最小二乗法と R² のつながり(概念レベル)
- 回帰モデルの当てはまりをどのように評価するか
- 実務で R² を使う際の注意点
統計検定・QC検定・データ分析の実務にも役立つ内容です。
決定係数とは
決定係数は寄与率ともいわれ、予測モデルのあてはまりの良さを示す指標です。
予測モデルにはいろいろありますが、どんな予測モデルであっても、決定係数によって、あてはまりの良さを示すことができます。
決定係数は、誤った認識をされることが多いのですが、これは、決定係数にははっきりとした定義がないからだと考えられます。
一般的な定義はこれなので、この式の意味を説明していきます。
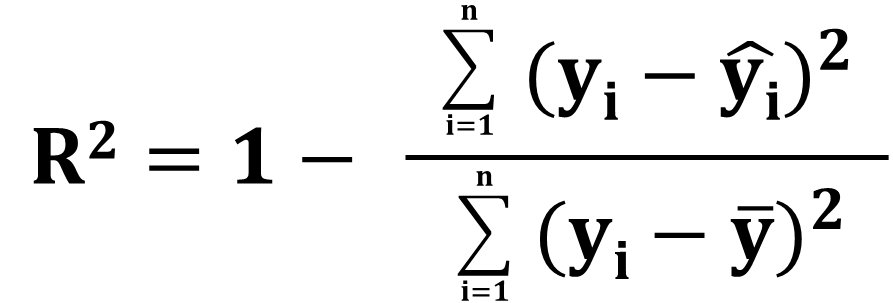
一般的なR2
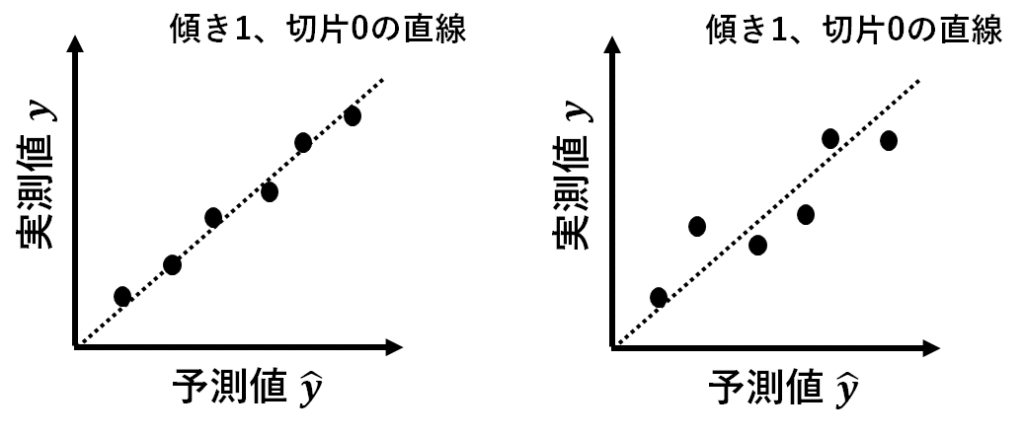
予測モデルにによる予測値を横軸、実測値を縦軸にとります。
ここに、傾き1、切片0の直線をひきます。
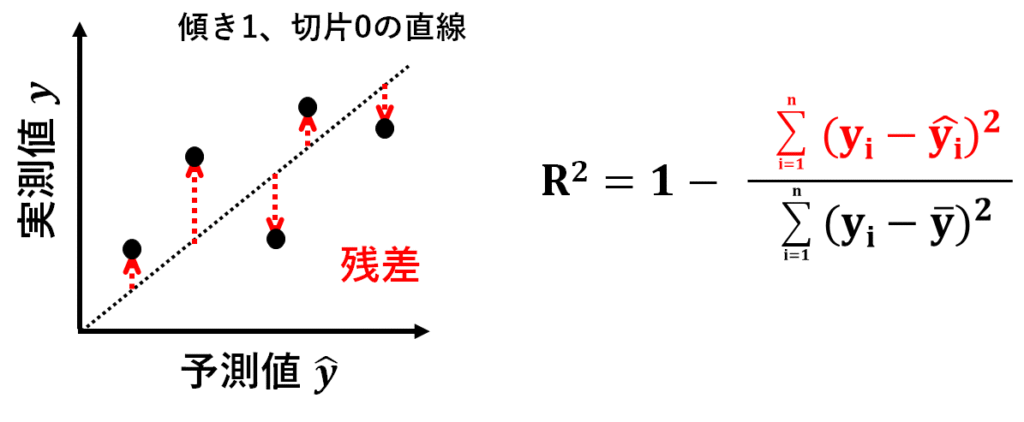
傾き1、切片0の直線上にプロットがある場合、その点は予測値と実測値が一致しているということになりますね。
つまり、この直線から実測値までの距離は、予測モデルで予測しきれなかった分を示します。
これを残差と言います。
この残差の大きさの程度を数値化したのが、決定係数R2です。
データ全体の残差の大きさを示すには、残差を二乗して全て足します(これを残差平方和と言います)。
それが、R2の計算式の中の赤字の部分です。
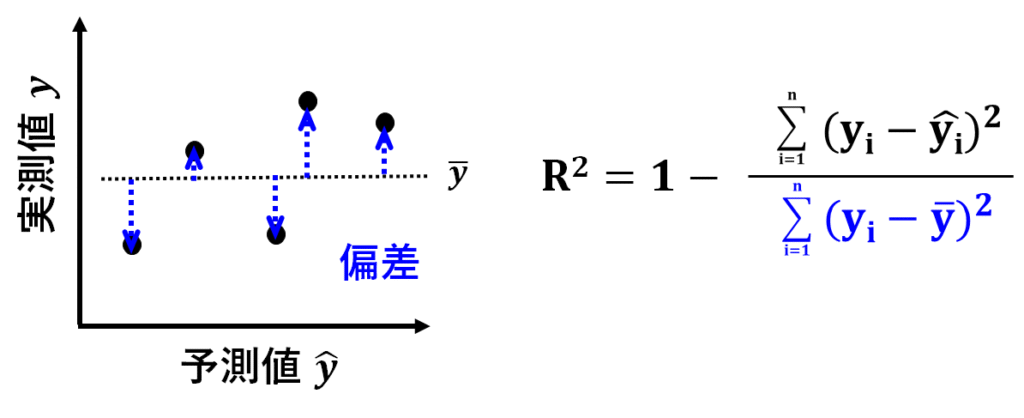
R2の計算式の中の青字の部分は、実測値yの偏差平方和ですね。
偏差平方和は、予測する前の、あるがままのyのばらつきを示しています。
R2は、1-「残差平方和(予測モデルで𝑦を予測しきれていない分)」÷「偏差平方和(あるがままの𝑦のばらつき)」で計算されているんですね。
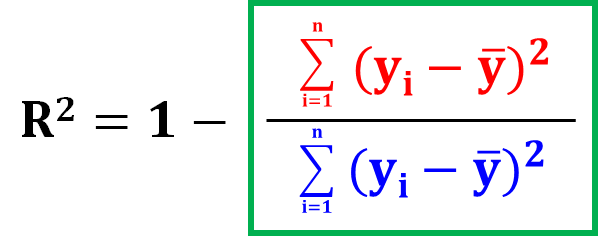
ここで、予測モデルは「予測すること」が目的なので、偏差平方和(あるがままの𝑦のばらつき)よりも、残差平方和(予測モデルで𝑦を予測しきれていない分)が大きくなることは通常は考えられませんよね。
よって、通常はこの緑枠の部分は1よりも小さくなります。
また、全ての点が傾き1、切片0の直線上にある時、それは、予測値=実測値であることを示しています。
この時、残差平方和は0になるため、緑枠の部分の計算結果は0になります。
つまり、この緑枠の部分は通常は0~1の範囲をとるということです。
ここで、決定係数R2は、予測モデルのあてはまりの良さを示す指標なので、よくあてはまっているほど大きい値になります。
よくあてはまっているときというのは、緑枠の部分の計算結果が小さい時ですよね。
1からこの緑枠の部分の計算結果をひいたものが、一般的な決定係数R2の定義です。
緑枠の部分が通常0~1の範囲をとるので、決定係数R2は、通常は0~1の範囲をとります。
”通常は”0から1の範囲をとる、なので、この範囲を外れることもあるということです。
緑枠の部分のは、分子も分母も二乗されているので、必ず0よりも大きくなるので、R2が1を超えることはないのですが、実は0を下回る場合があるのです。
R2=0になる場合
どういう場合にR2が0を下回るのかを説明するために、まずは、R2が0になる場合とはどんな時なのかを説明します。
最も簡単な単回帰分析を例に説明します。
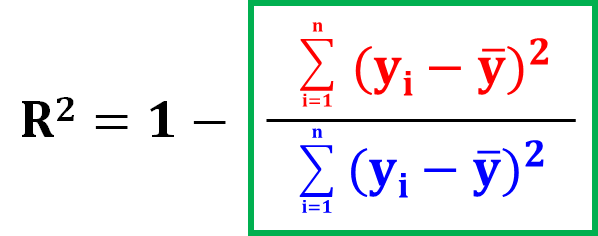
R2が0になる場合というのは、緑枠の部分の分母と分子が同じになる時ですよね。
予測モデルによって変化するのは分子の残差平方和のほうです。
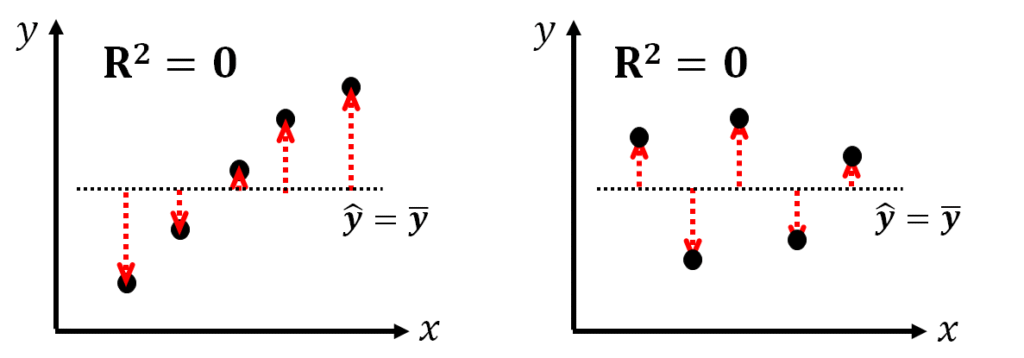
予測式が「=」であったなら、分母と分子は同じになりますよね。
この時、R2は0になります。
R2<0になる場合
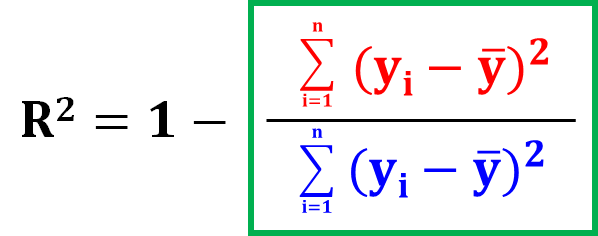
R2が0よりも小さくなる場合というのは、緑枠の部分が0よりも大きくなる時(つまり、分母の偏差平方和よりも、分子の残差平方和のほうが大きい時)ですよね。
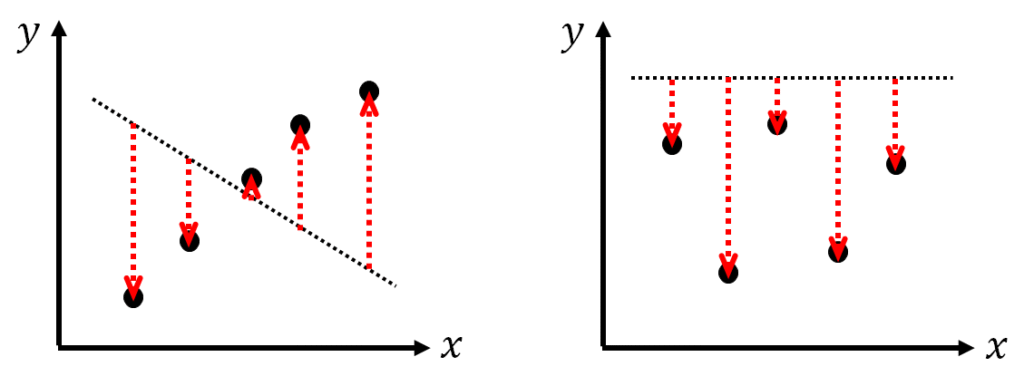
残差平方和が偏差平方和よりも大きくなる場合とは、例えば、右上がりの関係がありそうなのに、右下がりの予測モデルを構築した場合や、予測値が実測値の常に上にある状態の予測モデルの場合などです。
つまり、「全く予測できていない、適当な予測モデル」の場合には、残差平方和が偏差平方和よりも大きくなるので、緑枠の部分は1よりも大きくなり、R2は0よりも小さくなります。
ここで、実は、R2が絶対に0よりも小さくならない場合があります。
それは、最小二乗法によって予測モデルを構築した場合です。

最小二乗法による予測モデルのR2
最小二乗法で構築した予測モデルの場合は、R2が絶対に0よりも小さくならない理由を説明します。
偏差平方和をこのようにして展開していきます。

詳しい説明は省略しますが、最小二乗法では黒枠の部分は必ず0になります。
よって、偏差平方和は、予測値から平均値までの距離の二乗和と残差平方和を足した値と一致します。
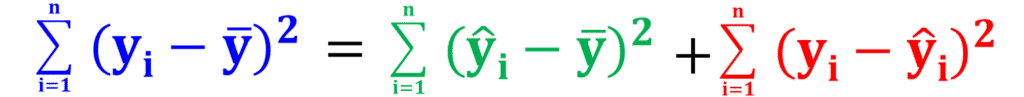
R2は「1-残差平方和÷偏差平方和」ですが、これは、上の関係式を使って、このように変換できますね。
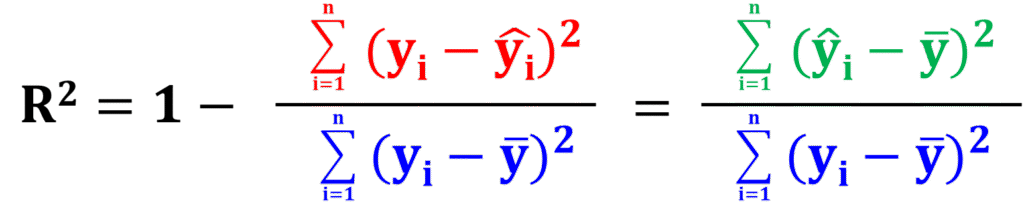
分母も分子も必ず正なので、R2が絶対に0よりも小さくならないですよね。
注意点
ここで、R2が大きいことは、予測モデルのあてはまりが良いことを示しますが、これはあくまでも予測モデル構築に使用したデータではあてはまりが良いことを示しているのであり、未知のデータでもあてはまりが良いということを示しているわけではありません。
例えば、この2つの予測モデル、左の方があてはまりがよいですね。
しかし、この結果をもって、左の予測モデルのほうが優れていると判断してしまうのはよろしくありません。
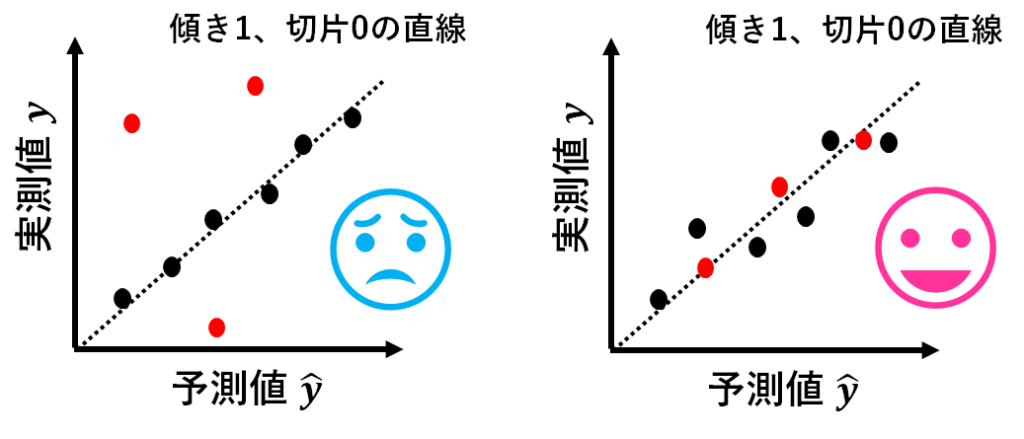
左の予測モデルは、モデル構築に使用したデータでは、あてはまりが良いですが、モデル構築に使用したデータ以外(赤点)をこの上にプロットしていったとき、予測値と実測値が全くマッチしないかもしれず、その場合、この予測モデルは良い予測モデルであるとは言えませんよね。
一方、右のようにモデル構築に使用したデータでもあてはまりがよく、モデル構築に使用したデータ以外(赤点)でも、モデル構築に使用したデータと同じ程度のあてはまりの場合、この予測モデルは良い予測モデルであると言えますよね。
まとめ
この記事では、回帰分析における決定係数 R² の基本的な考え方について解説しました。
- 決定係数R² は回帰モデルの当てはまりを評価するための基本的な指標
- R²は全体のばらつきに占める回帰式で説明できている割合
- 最小二乗法による回帰モデルの場合は、R² は必ず0~1
- 全く予測できていない、適当な予測モデルの場合は0を下回ることもある
- R²によってあてはまりの良さを評価できるモデルに制限はない
