

重回帰分析は、誤った結果の解釈をされやすい統計解析手法です。
この記事では、重回帰分析の基本的な概念やイメージを説明します。
回帰分析とは
回帰分析とは予測モデル構築手法の一種です。
結果を示す変数が、原因になる変数関数で予測されます。
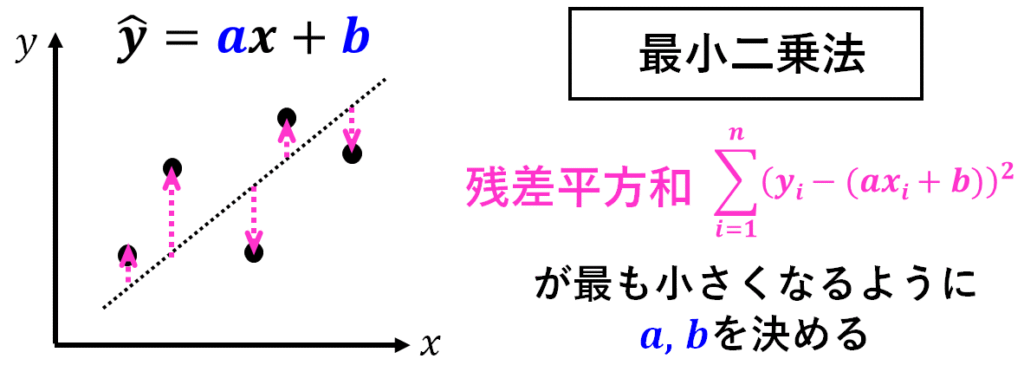
ここで、最もよく知られている回帰分析手法は、最小二乗法です。
最小二乗法とは、ある直線を引いたときに、その直線からの距離(これを残差と言います)が最も小さくなるように回帰直線の係数を算出する方法のことを言います。
データ全体の残差が最も小さくなる時というのは、残差を二乗して全て足した残差平方和が最も小さくなる時です。
つまり、残差平方和が最も小さくなるように回帰直線の係数を決めるのが最小二乗法です。

重回帰分析とは
最小二乗法による予測手法には、単回帰分析と重回帰分析があります。

重回帰分析は、MLRとも呼ばれます。
MLRは、Multiple Linear Regressionの頭文字です。
単回帰モデルは、1つの変数で予測モデルを構築するのに対して、重回帰モデルは、2つ以上の変数で予測モデルを構築します。
重回帰分析のメリット
重回帰分析を説明するのに、よく使われるのが、アパートの家賃の予測モデルです。
アパートの家賃が決まる要素を考えてみましょう。
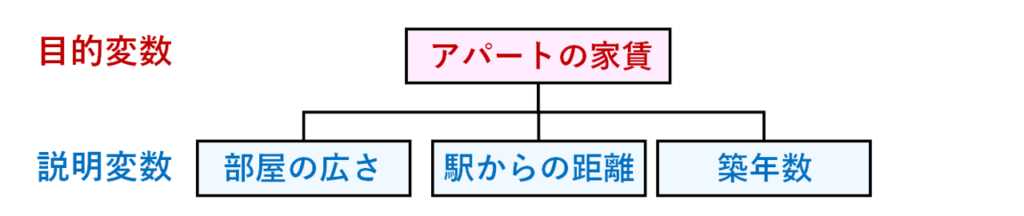
- 部屋が広いほど家賃は高くなる
- 駅からの距離が近いほど家賃は高くなる
- 築年数が新しいほど家賃は高くなる
アパートの家賃は、1つの要素だけではなくて、複数の要素が関係していますね。
このように、ある結果に影響を与える要素が複数ある場合には、重回帰分析で予測モデルを構築するのが有効なんです。
例えば、アパートの家賃に、「部屋の広さ」と「駅からの距離」と「築年数」が関わっているように、ある目的変数yの変動には、3つの説明変数x1,x2,x3が関わっているとしましょう。
そして、目的変数yを各説明変数x1,x2,x3単独で予測した単回帰分析の結果がこうなったとしましょう。
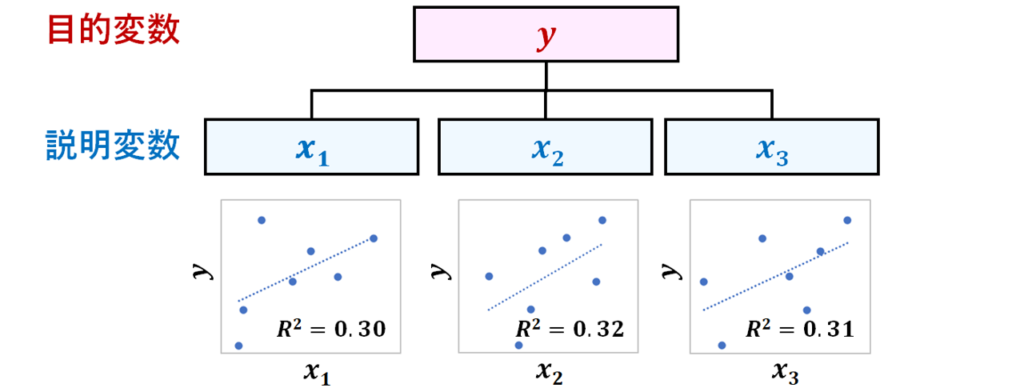
この結果をもって、各説明変数は目的変数に影響していると言えるでしょうか?
予測モデルのあてはまりの良さを示す指標であるR2はどれも0.3程度ですね。
一般的に、R2の目安として、0.5以上であればあてはまりが良いと言われていますので、0.3は、あてはまりがよいと言える値ではないということですね。
しかし、この例では、実は、目的変数を3つの説明変数によって予測した場合のR2は0.9になるんです。
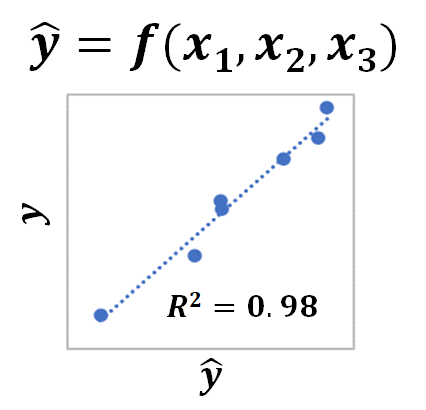
単独ではR2が0.3程度だったが、組み合わせるとR2が0.98になったということですね。
なぜこのようなことになるのでしょうか?
重回帰モデルのあてはまりが良い理由
今考えているのは、ある目的変数yの変動に、3つの説明変数x1,x2,x3が関わっている場合ですので、目的変数yをx1を使って予測したときの、回帰線からの距離『残差』は、x1では説明がつかないがx2とx3でなら説明がつく成分、ということになります。
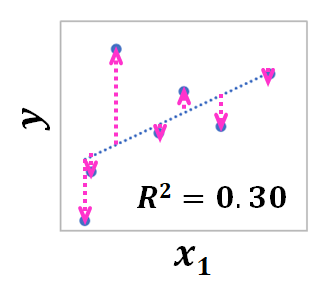
目的変数yをx1を使って予測したときの残差を縦軸にしてみましょう。
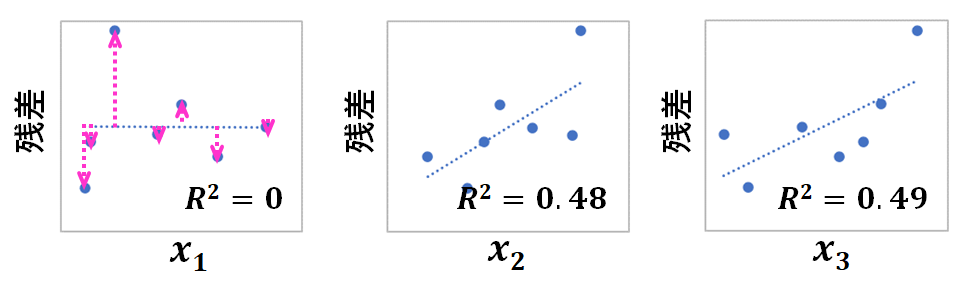
残差はx1では予測しきれない成分なので、当然、残差とx1には関係性がみられません。
一方で、残差とx2、残差とx3には関係性が確認できますね。
このとおり、ある目的変数に、複数の説明変数が関わっている場合では、1つの説明変数で目的変数を予測したときの残差は、他の説明変数と関わっている成分が含まれているんです。
だから、目的変数に確実に影響している説明変数によって目的変数を予測したとしても、単回帰分析ではR2が小さくなってしまう、というわけです。
重回帰分析のイメージ
重回帰分析のイメージはこうです。
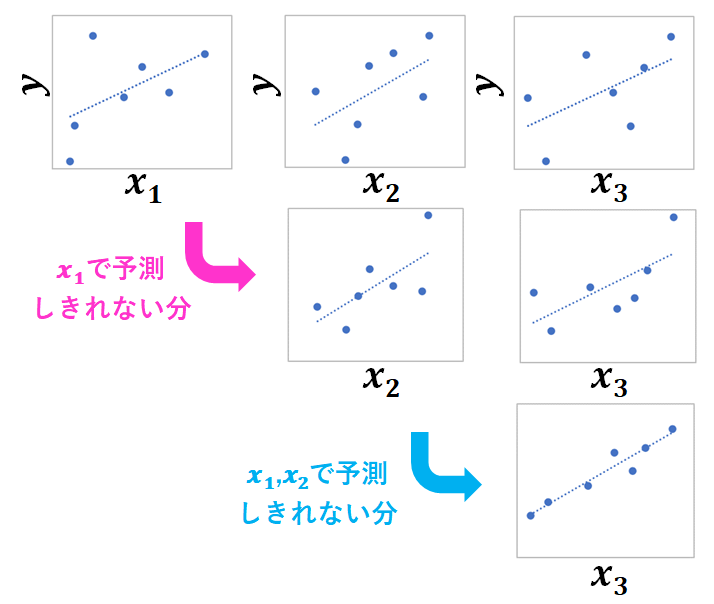
目的変数に確実に影響している説明変数が3つあったとしたら、ある説明変数で予測したときの残差が、他の説明変数でよく予測でき、さらにその残差が、また別の他の説明変数でよく予測できる、となるわけです。
重回帰分析のイメージは、このように理解するとわかりやすいと思いますが、実際には、このように段階的に予測するのではなくて、一気に予測モデルを構築します。
重回帰モデルの係数の計算
単回帰分析では、実測値と予測値の差分である残差の二乗の総和である、残差平方和が最小になるようにa,bを決めました。
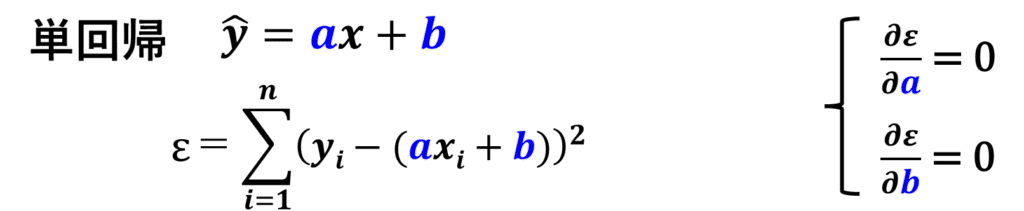
残差平方和をεとします。
残差平方和εが最小になる時というのは、εをaとbそれぞれで偏微分した値が0になる時なので、この連立方程式を解けばaとbが求まります。
重回帰分析でも同じ考え方です。
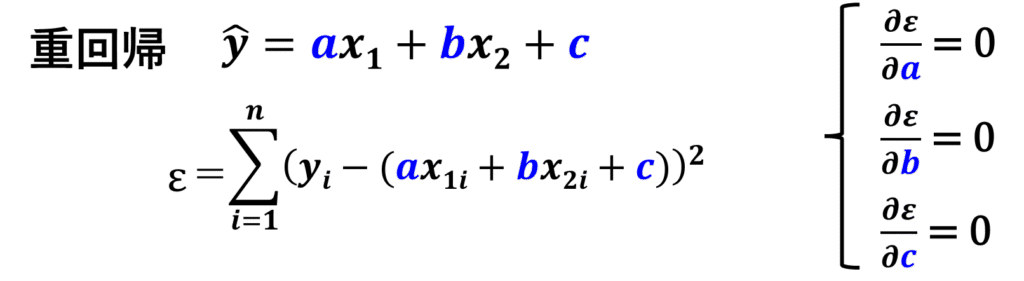
これは説明変数がx1とx2の2つある場合ですが、残差平方和が最小になる時というのは、εをa,b,cそれぞれで偏微分した値が0になる時なので、この連立方程式を解けば求まります。
説明変数がいくつになった場合でも、同じやり方です。
重回帰分析使用上の注意点
ここで、最小二乗法による重回帰分析を使用する際には、いくつかの注意点があります。
- 線形の関係しか予測できない
- 説明変数を増やすと、数学的にR2が大きくなる
- 説明変数間に相関関係がある場合、偏回帰係数の推定精度が悪くなる
この注意点を考慮せずに結果の解釈をしてしまうと、誤った結果の解釈でミスリードしてしまうことがありますので、重回帰分析を使用する際には、この注意点に関する知識が必須です。
まとめ
重回帰分析では、目的変数を複数の説明変数で予測します。
重回帰モデルは、このような線形結合の形のモデルです。
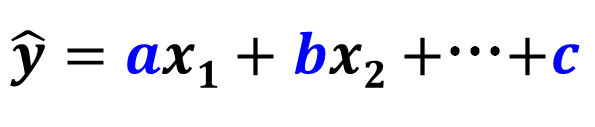
係数は最小二乗法で求めます。
目的変数に関連する説明変数が複数ある時には、一般的に、重回帰モデルがよくあてはまります。
しかし、重回帰分析を使用する際には、いくつかの重要な注意点があり、正しく使うためには、それらの注意点への配慮が必要です。
この記事のYouTube動画はこちら
